ITCOW牛新网 7月22日消息,字节跳动Seed团队今日发布全新Vision-Language-Action(VLA)模型GR-3,该模型在机器人多模态理解和复杂操作领域取得突破。配合自主研发的22自由度双臂机器人ByteMini,GR-3展现出对柔性物体的精准操控能力和对抽象指令的深度理解。

据ITCOW牛新网了解,GR-3的核心突破在于三大技术优势:
- 小样本学习能力:仅需10条VR采集的人类操作轨迹,即可将新物体操作成功率从60%提升至80%以上;
- 复杂任务处理:可完成包含10个以上子任务的餐桌整理,并精准响应分步指令;
- 柔性物体操控:在衣物整理等任务中实现双臂协同操作,成功率达业界领先水平。

技术架构方面,GR-3创新性地融合了遥操作机器人数据、VR采集的人类轨迹以及公开视觉语言数据。测试显示,该模型在未见过物体任务中的成功率较基准模型提升33.4%,在复杂指令理解方面提升42.8%。配套的ByteMini机器人凭借独特的球腕设计,可在狭小空间完成穿针引线级精细操作。
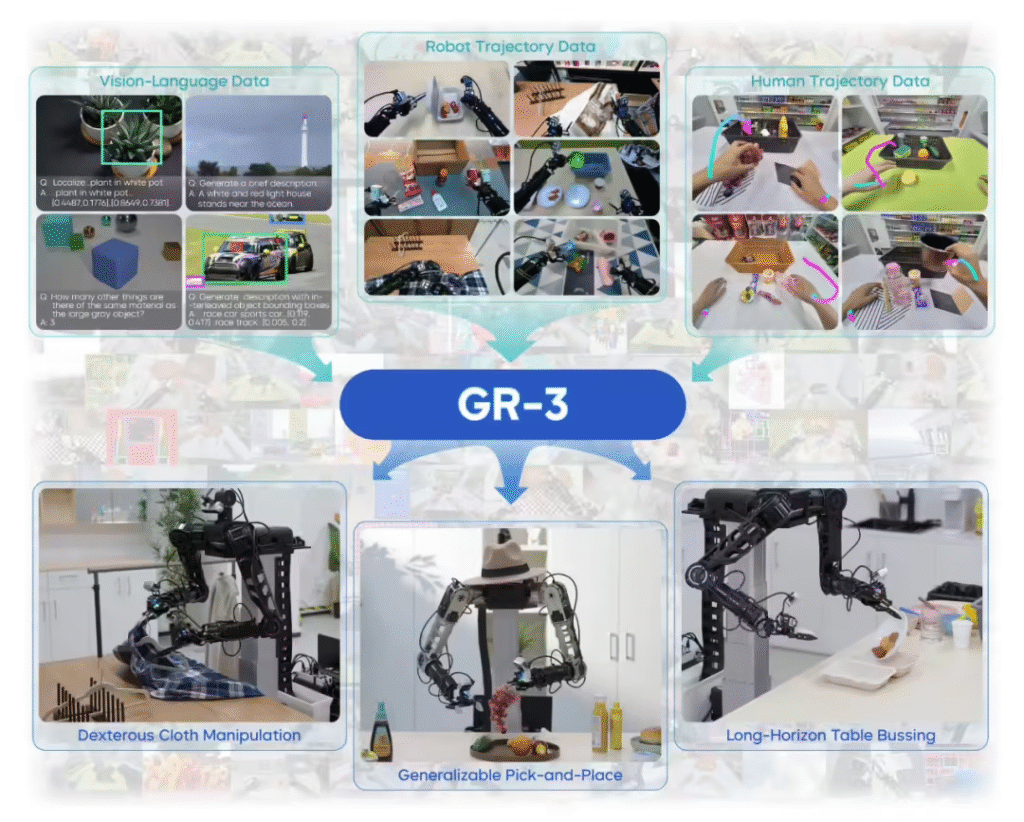
行业专家评价,GR-3的突破在于将大语言模型的抽象理解能力与机器人精准操控相结合,其”小数据大智能”的特点有望降低机器人普及门槛。