ITCOW牛新网 9月12日消息,阿里云通义团队今日正式发布新一代大语言模型架构Qwen3-Next,并同步开源基于该架构的80B-A3B系列模型。这一技术突破将显著提升大模型在长文本处理和大规模参数下的运行效率。

据了解,Qwen3-Next架构针对当前大模型发展的两大核心挑战进行了优化设计。该架构采用创新的混合注意力机制,结合Gated DeltaNet与Gated Attention技术,有效提升了长文本处理能力。同时,通过高稀疏度MoE结构设计,实现了800亿参数规模下仅激活30亿参数的运行效率。
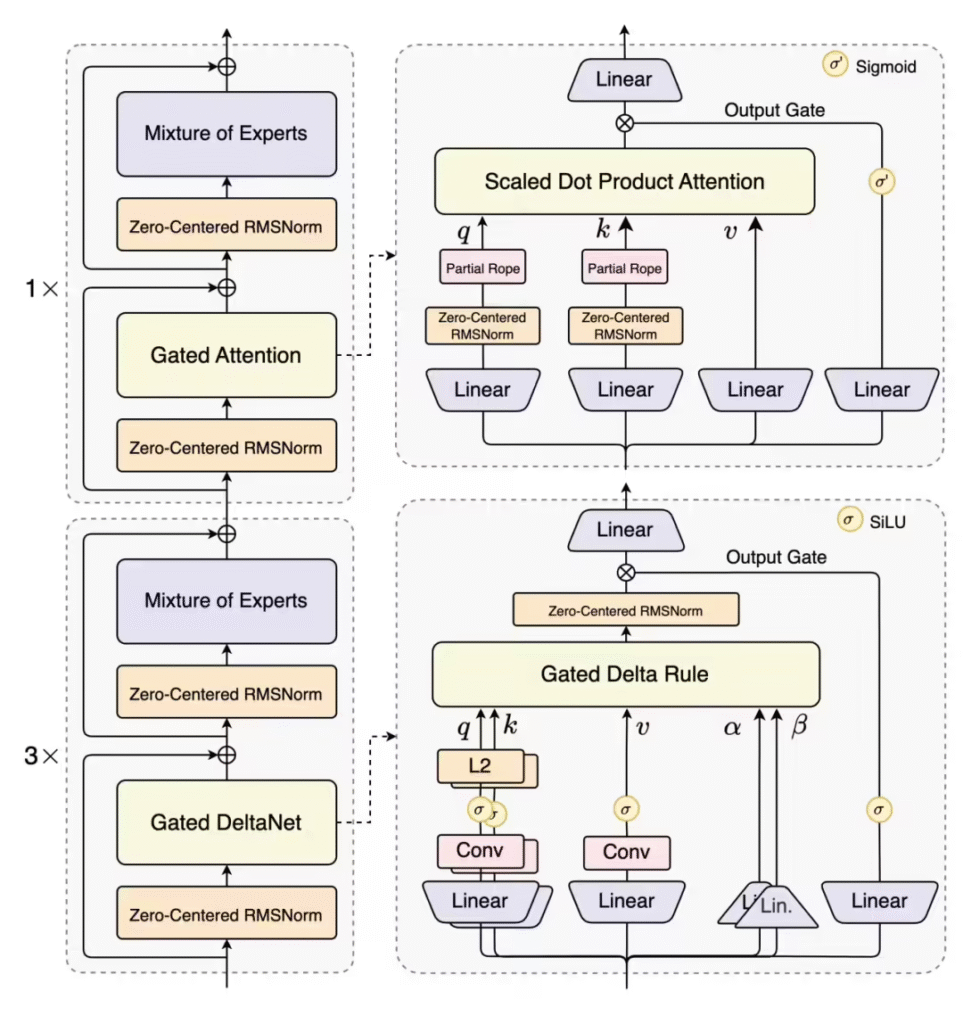
据ITCOW牛新网了解,新架构还引入了多token预测机制,大幅提升了模型的推理速度。在实际测试中,80B-A3B基础模型展现出与Qwen3-32B密集模型相当的性能,但训练成本仅为后者的十分之一,在32k以上长文本处理时的推理吞吐量更是达到十倍以上。
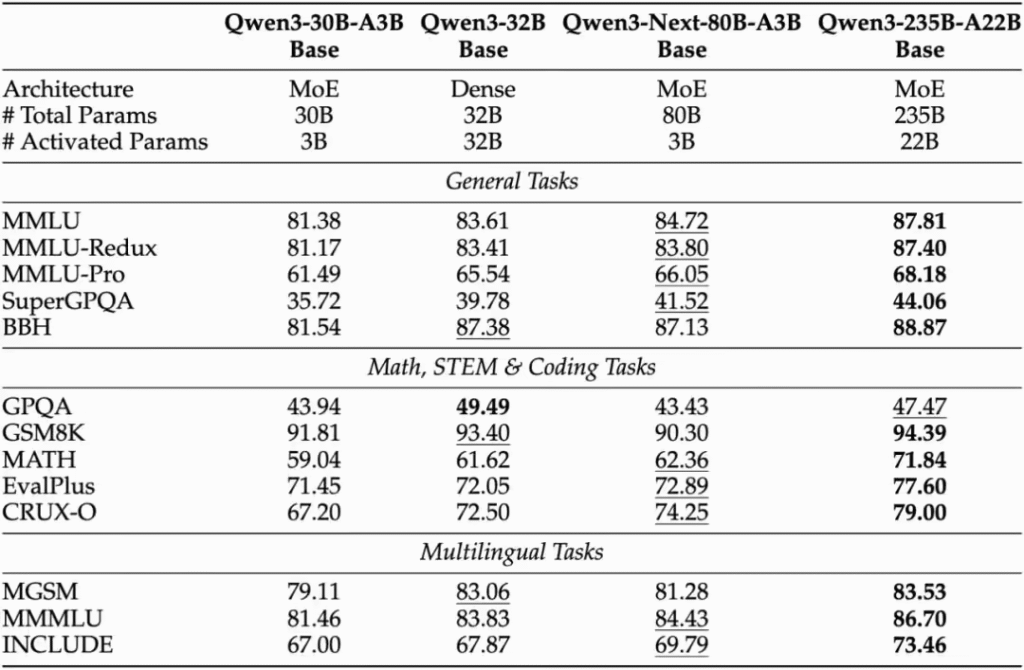
值得注意的是,新模型原生支持262k上下文长度,并可扩展至约101万tokens。其中Instruct版本在多项评测中接近235B参数规模的性能表现,而Thinking版本在复杂推理任务上甚至超越了业内知名模型。
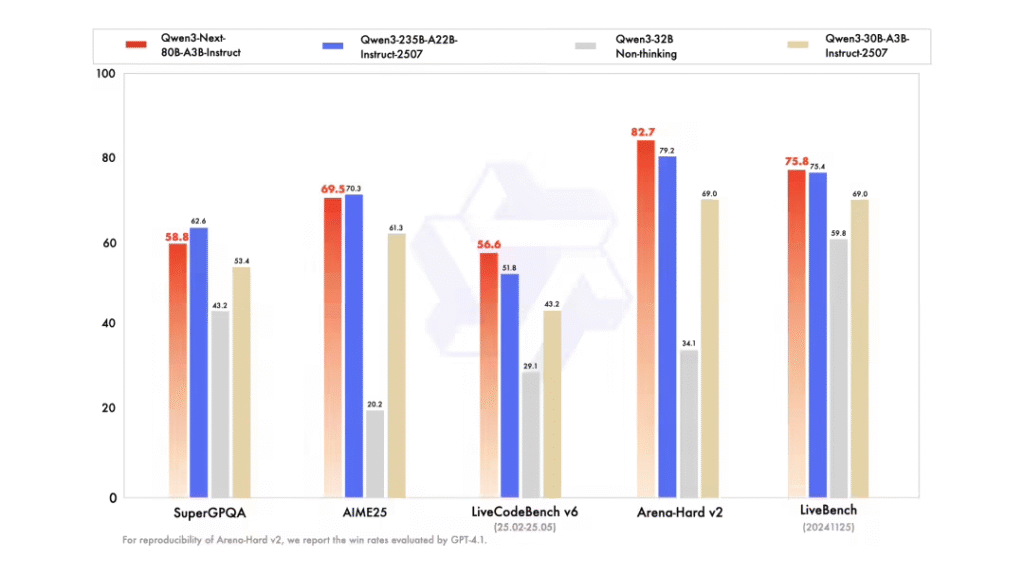
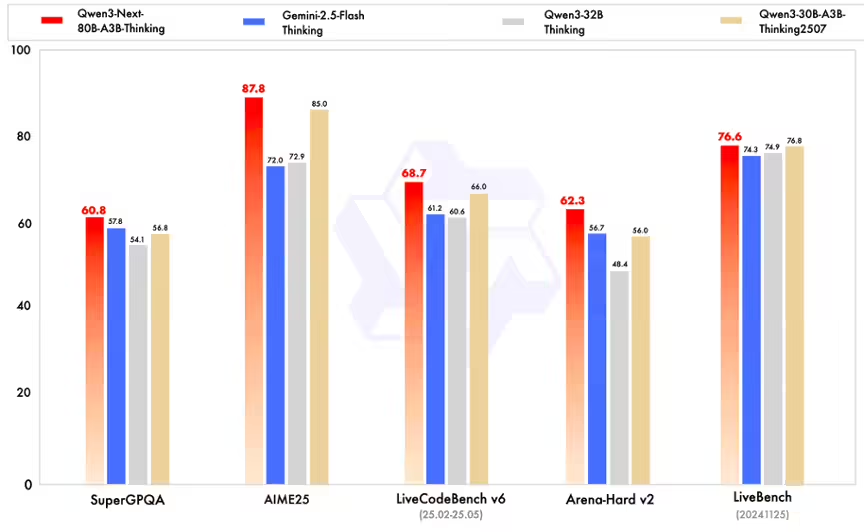
阿里云表示,该系列模型已在Hugging Face平台开源,采用Apache-2.0许可协议。开发者可通过Transformers、SGLang等主流框架进行部署,同时OpenRouter平台也已提供相关服务。这一开源举措将进一步推动大模型技术在产业界的应用创新。