ITCOW牛新网 9月14日消息,百度近日在Hugging Face平台正式发布新一代文字识别解决方案PP-OCRv5。这款专为文本识别任务优化的AI模型,在多项性能测试中超越了包括GPT-4o在内的主流视觉语言模型。
据了解,PP-OCRv5采用模块化两阶段设计,专注于解决通用大模型在文本定位和边界框精度方面的不足。该模型参数量仅为0.07B,在英特尔至强Gold 6271C CPU上可实现每秒处理超过370个字符的高性能表现。
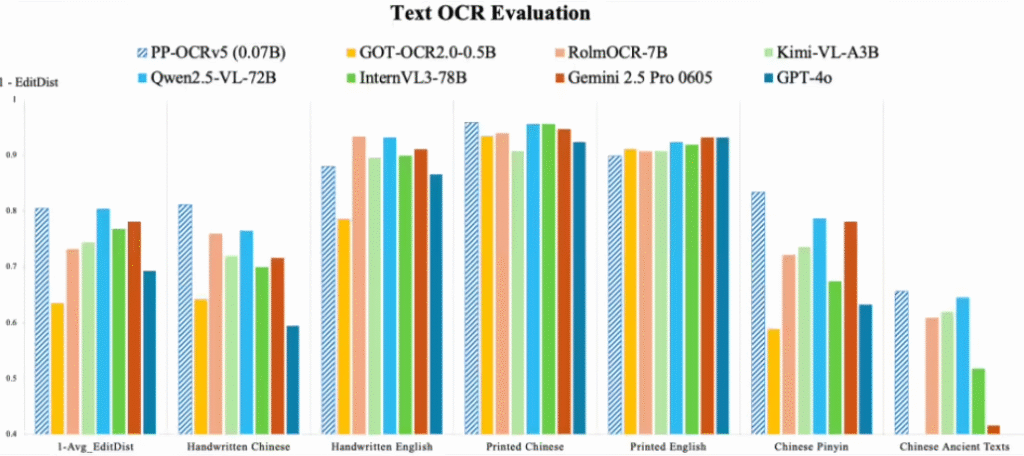
据ITCOW牛新网了解,PP-OCRv5在OCR专项测试中展现出卓越性能,对手写和印刷体的中英文及拼音文本识别准确率均超过Gemini 2.5 Pro、Qwen2.5-VL和GPT-4o等知名模型。同时,该模型支持简体中文、繁体中文、英文、日文和拼音五种文字的直接识别,并能处理超过40种语言的文本。
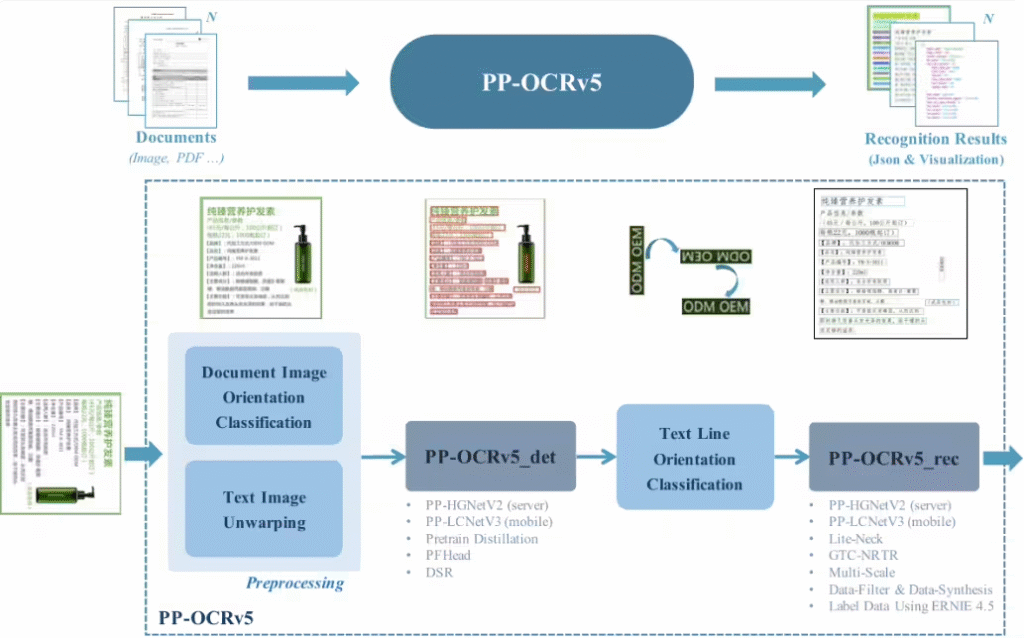
值得注意的是,PP-OCRv5采用四阶段处理流程,包括图像预处理、文本检测、方向分类和文本识别,确保从图像中精准提取结构化数据。目前该模型已在Hugging Face平台开源,开发者可免费获取使用。