ITCOW牛新网 10月20日消息,DeepSeek-AI团队今日开源创新模型DeepSeek-OCR,该技术通过视觉模态实现对长文本的高效压缩,为历史文档数字化和大语言模型训练提供新解决方案。模型已同步在GitHub和Hugging Face平台开放,参数量为3B。
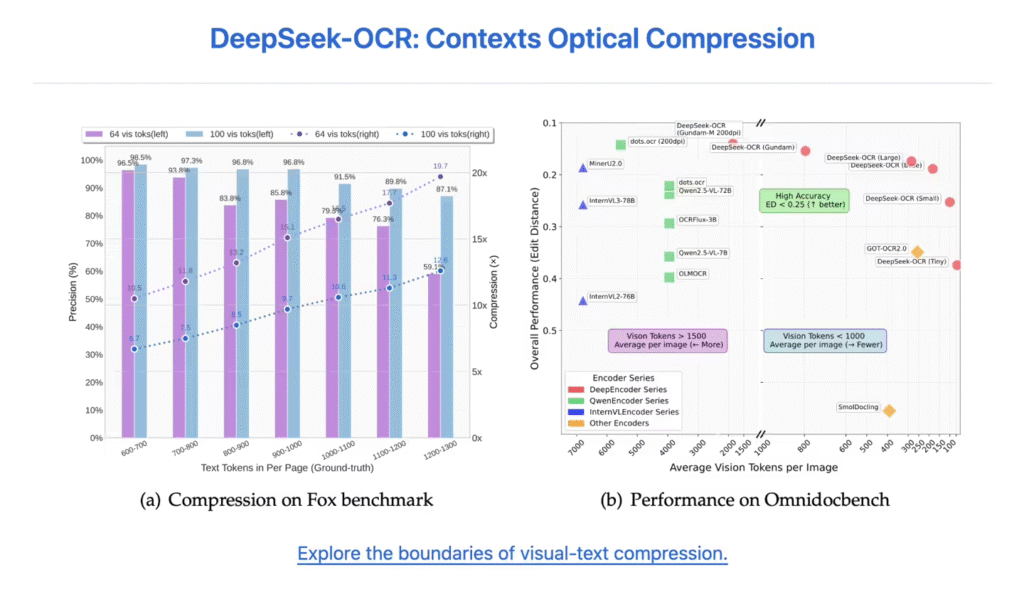
DeepSeek-OCR采用双模块架构,核心编码器DeepEncoder专为高分辨率输入优化,在保持低计算激活的同时实现高压缩比。测试数据显示,当文本token数量不超过视觉token的10倍时,模型OCR精度达97%;即使压缩比提升至20倍,准确率仍稳定在60%左右。
据ITCOW牛新网了解,该模型在OmniDocBench基准测试中表现突出:仅用100个视觉token即超越GOT-OCR2.0模型(每页需256个token),而不到800个视觉token的效果优于MinerU2.0模型(每页超6000个token)。实际应用中,单张A100-40G显卡可日均生成超20万页训练数据。


分析指出,DeepSeek-OCR的创新性在于将视觉压缩与文本处理结合,显著降低长文档处理的算力需求。这一技术不仅适用于古籍数字化等文化保护场景,还可优化大语言模型的记忆机制设计,推动多模态AI技术向轻量化、高效化发展。