ITCOW牛新网 11月12日消息,腾讯公司今日宣布,其微信团队研发的开源模型KaLM-Embedding在MTEB(大规模文本嵌入基准)多语言通用Embedding模型评测中取得全球第一的成绩。该模型在涵盖1038种语言、包含131项任务的评测体系中表现优异。
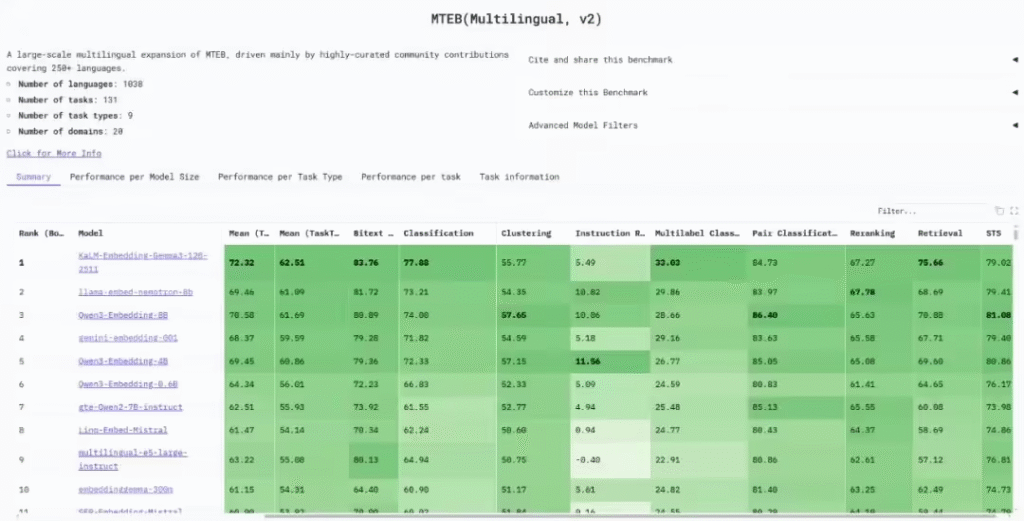
据了解,此次登顶的模型为KaLM-Embedding-Gemma3-12B-2511,拥有120亿参数,是MTEB榜单上规模最大的Embedding模型之一。该模型在跨语言语义对齐、数据质量、训练策略和维度嵌套等方面均有显著优化,综合得分分别达到72.32(Mean Task)和62.51(Mean TaskType)。
Embedding模型作为人工智能语义理解的核心技术,能够将文本转化为高维向量,实现非结构化内容的度量和检索。在RAG(检索增强生成)等架构中,Embedding模型通过从知识库中精准检索语义相关信息,构建高质量上下文,有助于提升大模型生成结果的准确性,减少”幻觉”现象。
腾讯已公开模型在Hugging Face平台的获取地址、技术论文和讨论反馈渠道,并采用MIT开源协议,支持商业使用。业内分析认为,此次开源将促进技术的广泛传播和应用,推动全球自然语言处理技术的发展。随着多语言处理需求的增长,KaLM-Embedding的突破将为跨语言信息检索、智能客服、内容推荐等应用场景提供更强有力的技术支持。