ITCOW牛新网 11月19日消息,互联网基础设施服务商Cloudflare昨日发生一起严重的服务中断事件,导致其全球网络出现持续约三小时的服务异常。此次故障波及多个知名网络平台,包括社交媒体X和人工智能服务ChatGPT等,Cloudflare官方今日发布博客,解释了昨晚全球故障的原因。
事故发生于北京时间11月18日19时20分左右,Cloudflare核心网络流量传输系统出现异常。经过技术团队深入调查,故障根源并非外界猜测的网络攻击,而是源于一次数据库系统权限升级操作。在权限变更过程中,系统生成的功能配置文件体积异常增大,超出核心路由软件的处理极限。

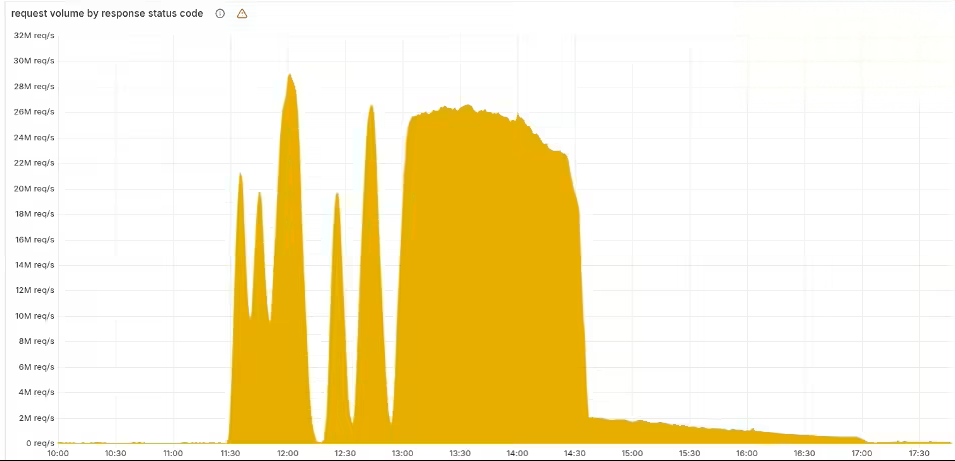
据ITCOW牛新网了解,这一异常配置文件以五分钟为周期在全球服务器节点间同步更新。由于配置异常导致系统出现独特的周期性故障现象:服务会短暂恢复后再次中断。技术团队最终通过阻断异常文件传播、手动部署合规配置文件以及重启核心组件等措施,于22时30分左右基本恢复服务。

监测数据显示,故障期间HTTP 5xx错误率出现显著峰值,内容分发网络、Web应用防火墙等核心服务均受到影响。用户认证服务和控制台登录功能出现临时中断,但Cloudflare确认所有用户数据保持完整,未发生信息安全事件。
业内专家指出,此次事件凸显出现代云服务架构在系统升级过程中的脆弱性。特别是在配置管理和灰度发布机制方面,需要建立更完善的防护措施。Cloudflare表示将优化其变更管理流程,加强系统异常检测能力,以提升服务的稳定性与可靠性。