ITCOW牛新网 12月12日消息,蚂蚁技术研究院今日正式开源LLaDA 2.0系列离散扩散大语言模型(dLLM),包含16B迷你版和100B旗舰版两个版本。这是业内首个参数量突破千亿的扩散语言模型,标志着扩散模型首次在超大规模参数下实现技术可行性验证。
据ITCOW牛新网了解,该模型采用混合专家架构(MoE),通过创新的Warmup-Stable-Decay持续预训练策略,可无缝继承现有自回归模型的知识体系,避免从头训练的高成本问题。在技术实现上,团队开发了置信度感知并行训练和扩散模型版DPO优化方法,在保证生成质量的同时实现2.1倍推理加速。
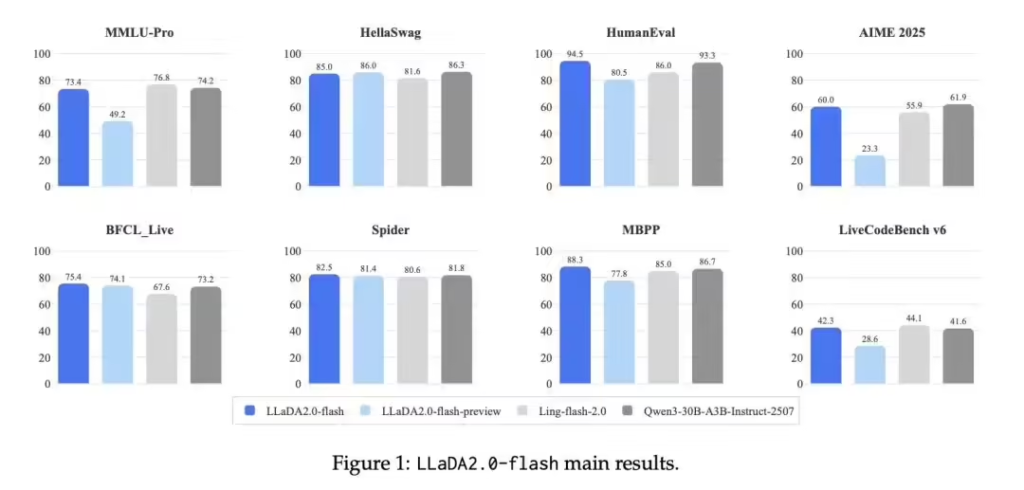
性能测试显示,LLaDA 2.0在代码生成等结构化任务中表现突出,在数学推理和智能体任务上超越同级自回归模型,其他领域与主流开源模型持平。蚂蚁技术研究院表示,这一突破证明了扩散模型在超大规模参数下不仅具备可行性,更能实现更强性能和更快速度。
目前,模型权重及完整训练代码已在Huggingface平台开源,为自然语言处理领域提供新的技术路径。业内分析认为,此举将推动扩散模型在代码生成、智能体开发等场景的规模化应用,加速AI技术的产业落地进程。