ITCOW牛新网 12月16日消息,字节跳动Seed团队今日正式发布新一代音视频创作模型Seedance 1.5 pro。该模型突破性地实现了音视频联合生成功能,能够基于文本或图像输入,同步生成带有声音的视频内容。

Seedance 1.5 pro采用基于MMDiT架构的音视频联合生成框架,通过深度跨模态信息交互机制,实现了视觉与听觉流在时间同步与语义一致性上的精准协同。与传统”视频生成+后期配音”的级联方式不同,该模型在生成画面每一帧的同时,由同一套神经网络同步生成对应的声音波形,从根本上解决了”口型对不上”、”声画不同步”等长期痛点。
与Seedance 1.0版本侧重运动稳定性不同,1.5 pro版本在视听协同、视觉张力和叙事协调性等方面实现多项突破。模型支持精准音画同步,能够捕捉多语种及方言的独特语音韵律与情感张力,原生支持中文、英文、日文、韩语、西班牙语、印尼语等语种,以及四川话、粤语等多种方言口音。在视频层面,模型具备自发的镜头调度能力,可执行长镜头跟随、希区柯克变焦等高难度运镜,实现电影级的画面衔接与专业影调。
在综合评测中,Seedance 1.5 pro各项关键能力处于业界前列水平。评测显示,模型对动作、镜头等复杂指令的理解相对精准,动态表现饱满,人物表情特写生动,复杂运镜相对流畅且与参考图风格衔接自然统一。在音频生成方面,模型在音频指令遵循、音画同步、音质与表现力等维度表现稳定且均衡,生成的人声相对更自然、机械感更少,音效真实感与空间混响较为贴近实际。
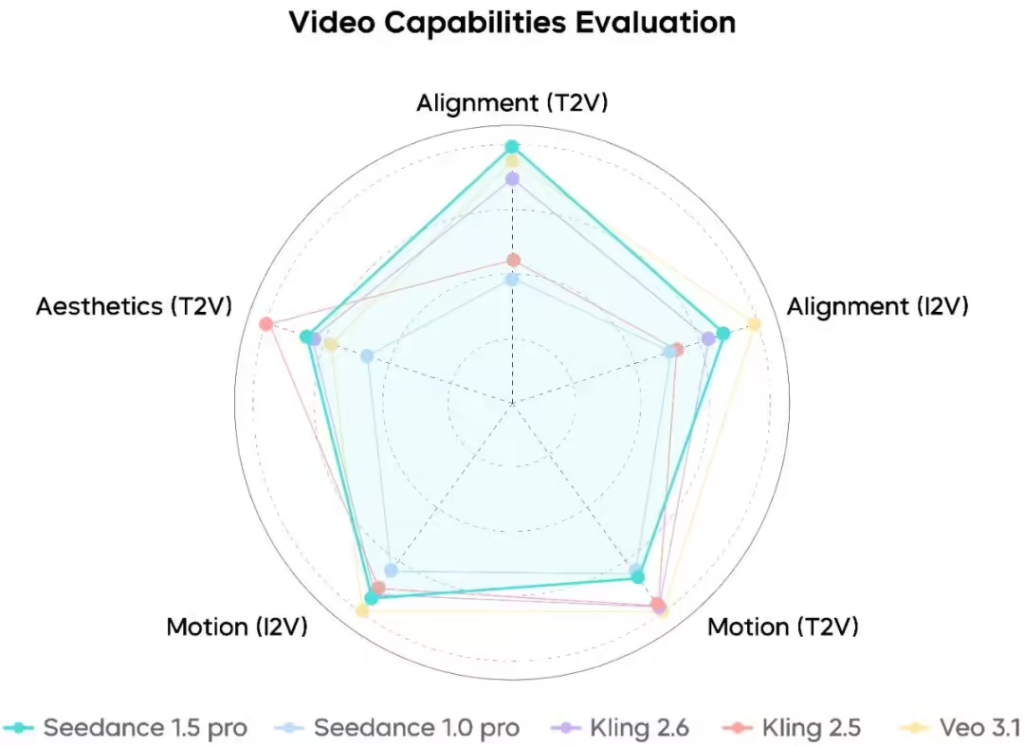
通过多阶段蒸馏框架和推理基础设施优化,Seedance 1.5 pro实现了超过10倍的端到端推理加速,大幅降低了生成所需的函数评估次数。这意味着生成一段高质量的音视频内容,用户等待的时间将大幅缩短,让专业级的内容创作不再遥不可及。
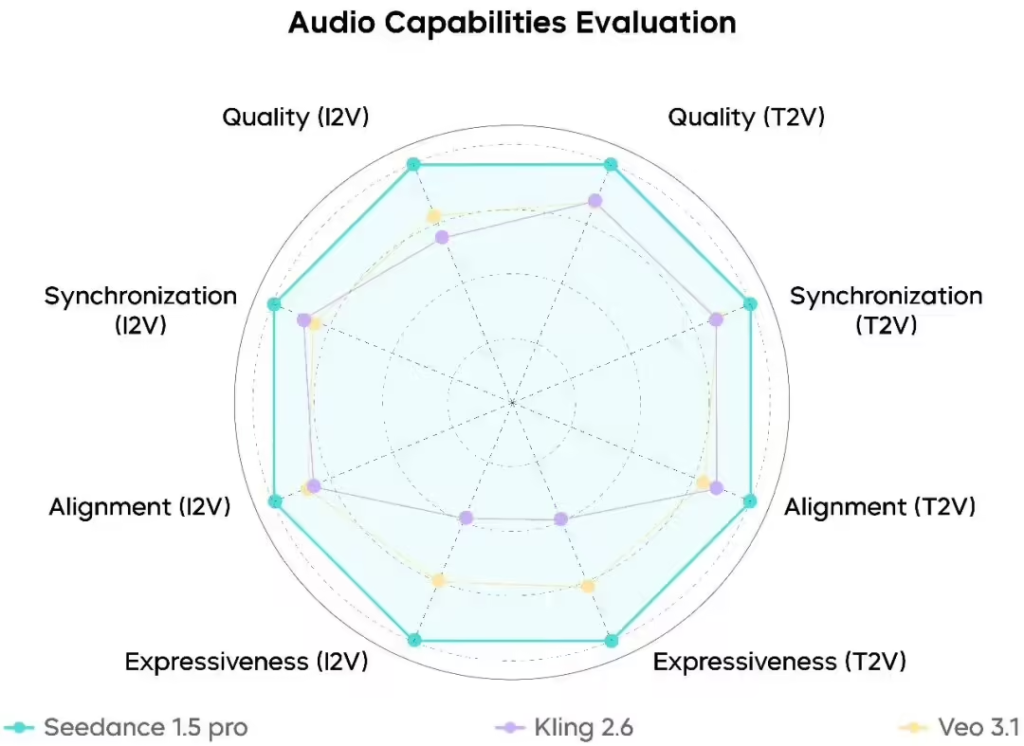
Seedance 1.5 pro可有力支持影视创作、短剧生成、广告生产及戏曲演绎等场景。在I2V任务中,模型展现出较强的风格一致性,有效保持了多镜头切换与复杂运动中的人物特征稳定,提升了从素材片段到成片制作的连贯性。目前,该模型已上线即梦AI和豆包平台,开发者可通过官方地址(https://seed.bytedance.com/seedance1_5_pro)获取详细技术文档与评测报告。