ITCOW牛新网 1月27日消息,DeepSeek今日推出新一代文档识别模型DeepSeek-OCR 2。该模型在前代基础上进行了架构优化,核心突破在于采用了全新的视觉编码器设计,通过引入“视觉因果流”技术,使机器能够更贴近人类的阅读逻辑处理复杂版式文档。
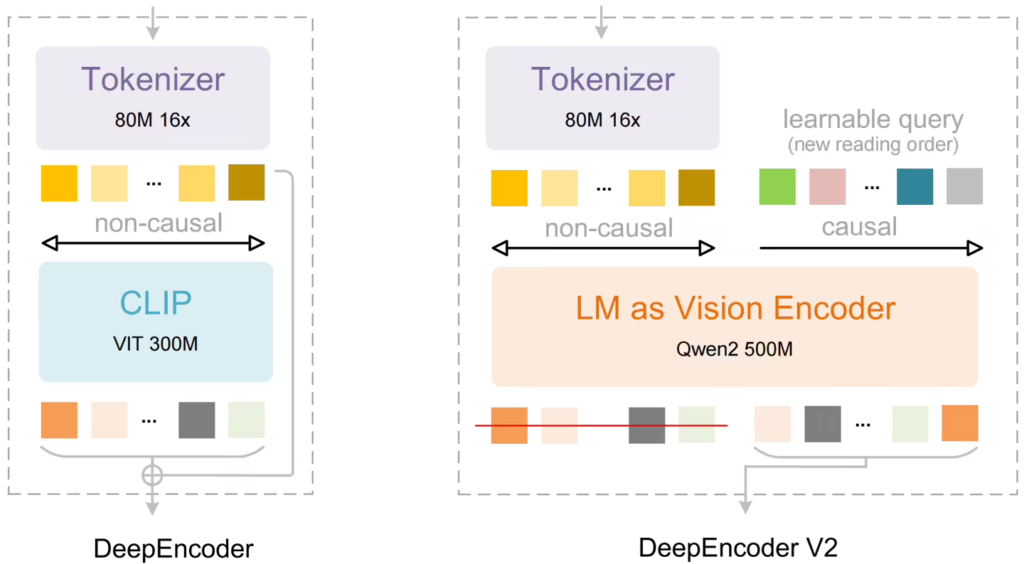
新模型采用名为DeepEncoder V2的新型编码器结构,取代了传统的基于CLIP的视觉编码模块。这一设计通过可学习的“因果流查询token”和定制化注意力机制,在保留视觉token全局双向注意力的同时,实现动态顺序重排。这种处理方式与人类阅读文档时基于语义进行跳跃式浏览的模式更为接近,特别适用于处理学术论文、杂志、报告等版式复杂的文档材料。
据ITCOW牛新网了解,在技术架构上,DeepSeek-OCR 2保持了编码器-解码器的基本框架。图像首先经过视觉tokenizer压缩处理,然后由DeepEncoder V2进行语义建模和顺序重组,最后交由基于混合专家架构的语言模型解码生成识别结果。这一设计在不显著增加计算负担的前提下,将单页文档的视觉token数量控制在256到1120之间。
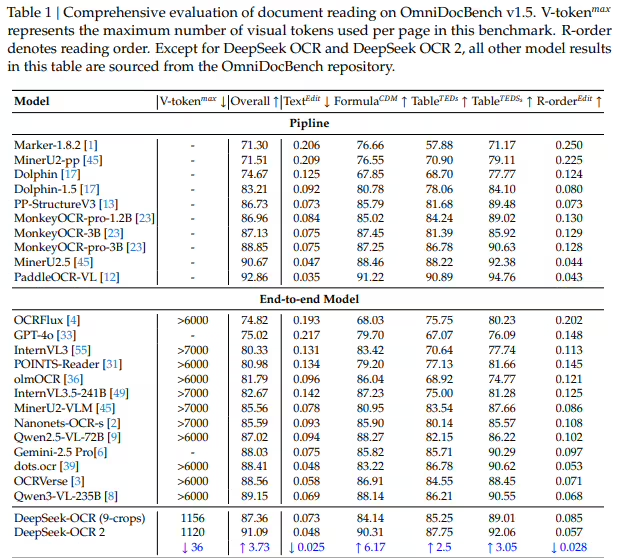
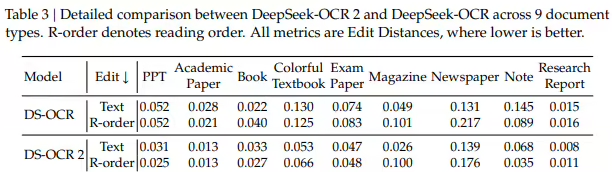
测试结果显示,在OmniDocBench v1.5基准测试中,DeepSeek-OCR 2的综合得分达到91.09%,较前代提升3.73%。在文档阅读顺序相关的编辑距离指标上表现尤为突出,表明模型在理解文档逻辑结构方面取得显著进展。在实际应用场景中,新模型在在线OCR服务和批量PDF预处理环境下的输出重复率均低于前代,展现出更稳定的性能表现。