ITCOW牛新网 1月29日消息,阿里千问团队昨晚宣布开源Qwen3-ASR系列语音识别模型,该系列包含Qwen3-ASR-1.7B与Qwen3-ASR-0.6B两个语音识别模型,以及一个创新的语音强制对齐模型Qwen3-ForcedAligner-0.6B。这些模型基于创新的预训练AuT语音编码器与Qwen3-Omni基座模型的多模态能力开发,在语音识别领域实现重要突破。
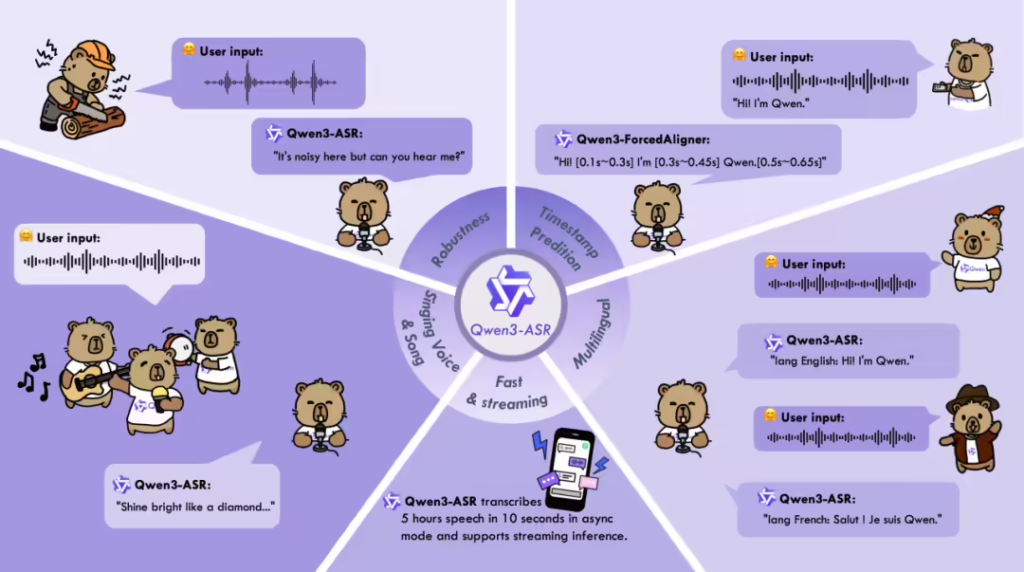
新推出的语音识别模型具备多语言处理能力,支持52种语言与方言的识别功能。其中1.7B参数模型在中文、英文、中文口音与歌唱识别等复杂场景下达到当前最优水平,展现出强大的复杂文本识别能力与抗噪声干扰性能。0.6B参数版本则在性能与效率间取得平衡,在128并发异步服务推理环境下可实现2000倍吞吐提升,仅需10秒钟即可处理超过5小时的音频内容。
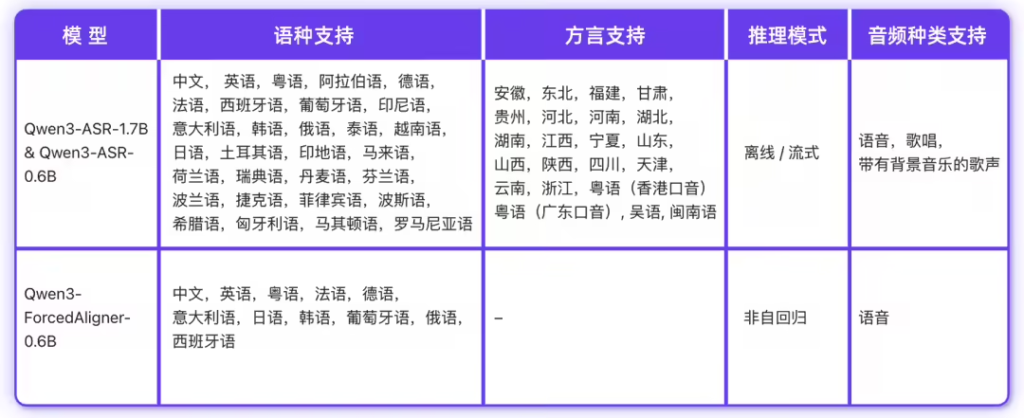
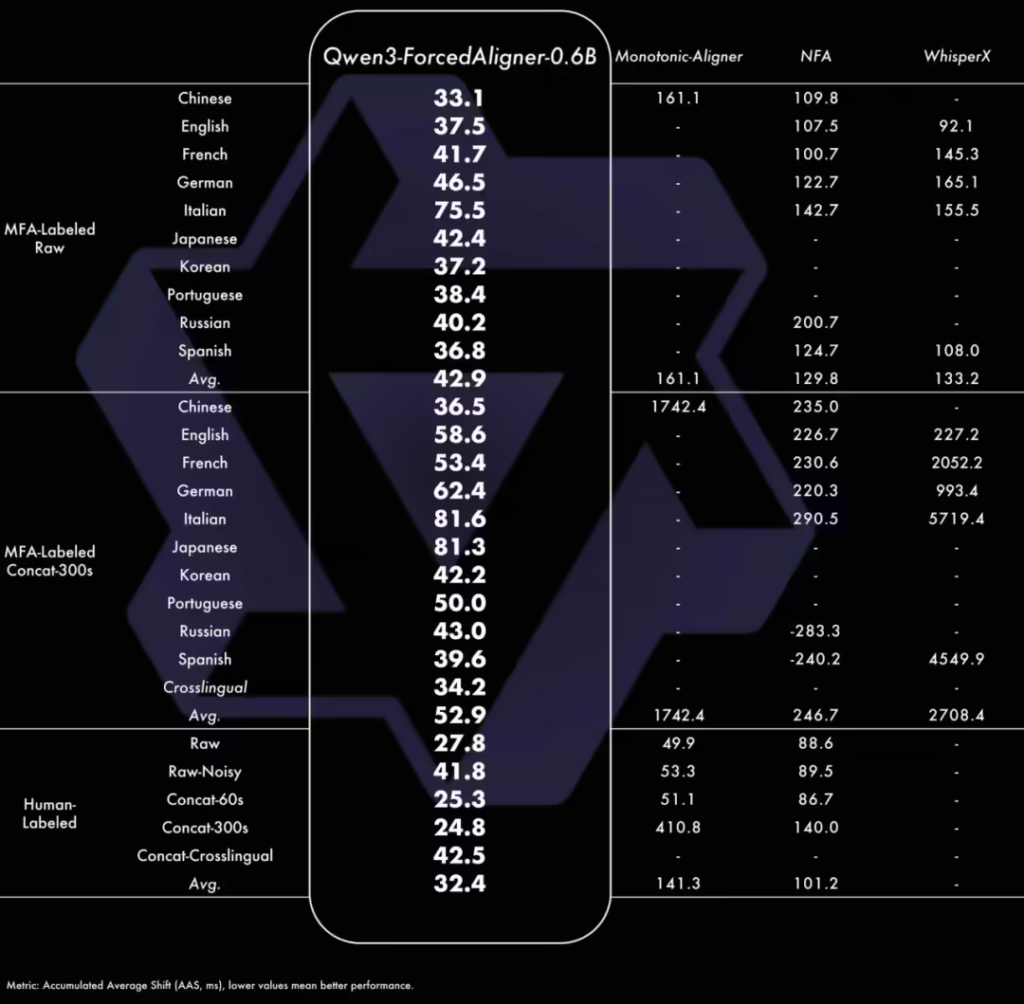
据ITCOW牛新网了解,此次同步开源的Qwen3-ForcedAligner-0.6B强制对齐模型采用了基于NAR LLM推理的时间戳预测方案,支持11种语言的精准时间戳标注,其预测精度超越传统WhisperX、Nemo-Forced-Aligner等工具,单并发推理RTF效率达到0.0089。该系列模型均支持流式与非流式一体化推理,最长可一次性处理20分钟音频。
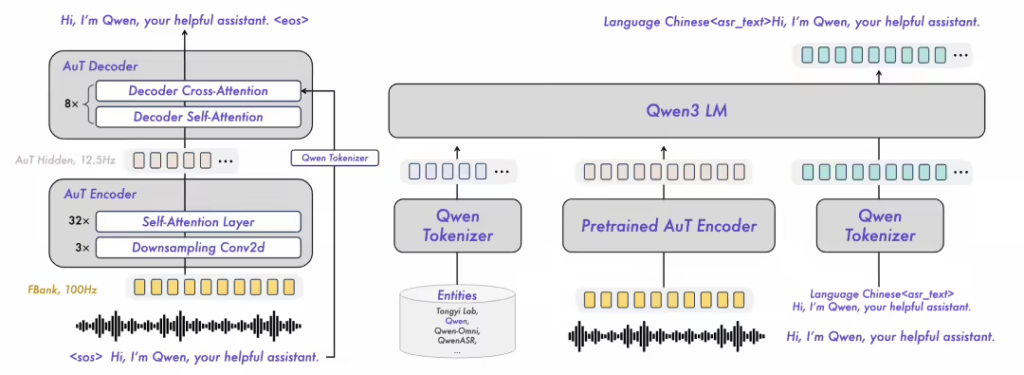
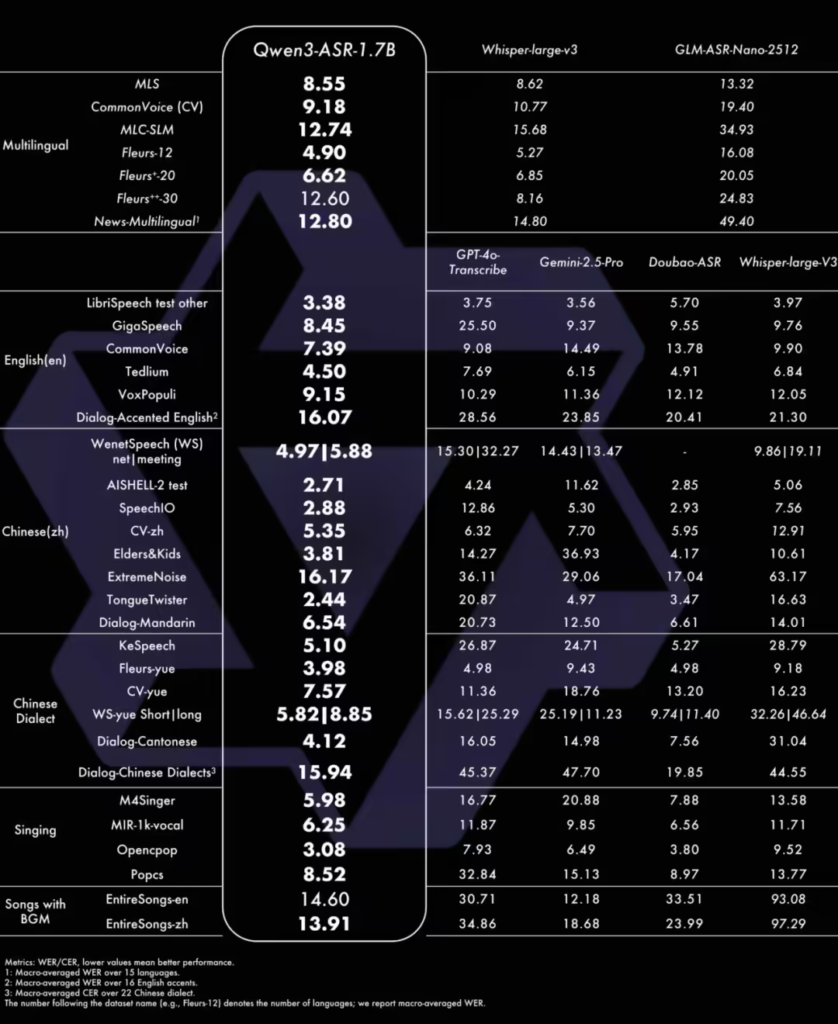
阿里千问团队表示,此次开源旨在推动语音识别与理解技术的研究发展,三个模型的完整结构、权重及配套推理框架已同步公开。该系列模型在复杂声学环境、多语言场景及特殊应用如歌唱识别等方面均表现出色,为语音处理领域提供了新的技术解决方案。