ITCOW牛新网 2月10日消息,苹果公司与中国人民大学近日联合发布名为VSSFlow的人工智能模型,首次实现在单一系统中从无声视频同步生成高保真环境音效与人类语音。该技术突破解决了传统音频生成模型功能单一的问题,通过联合训练机制使语音与音效生成产生协同优化效应。

VSSFlow采用10层神经网络架构,创新引入“流匹配”技术,使模型能够从随机噪声中自主重构目标声学信号。研究团队在混合数据集(含环境音视频、字幕视频及纯文本语音数据)训练中发现,语音与音效数据的联合训练不仅未产生干扰,反而形成“互助效应”——语音训练提升音效生成质量,音效数据优化语音表现。
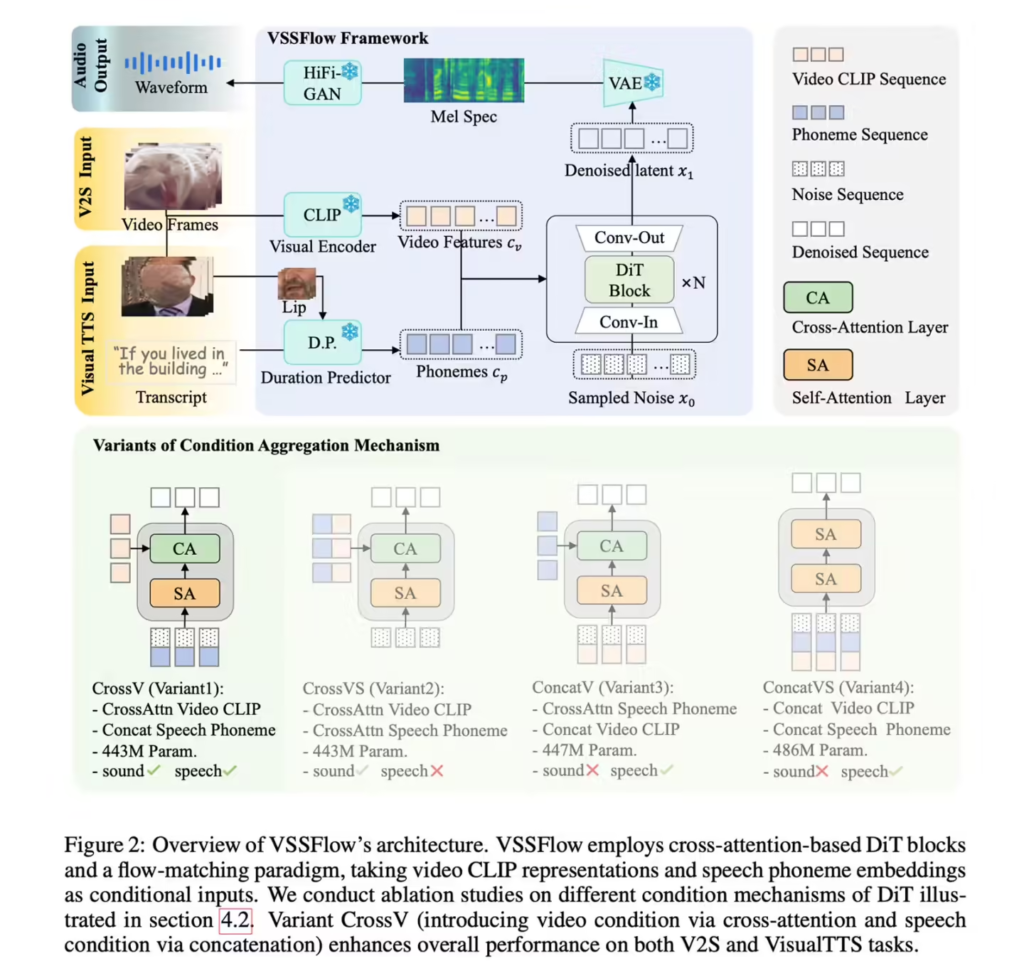
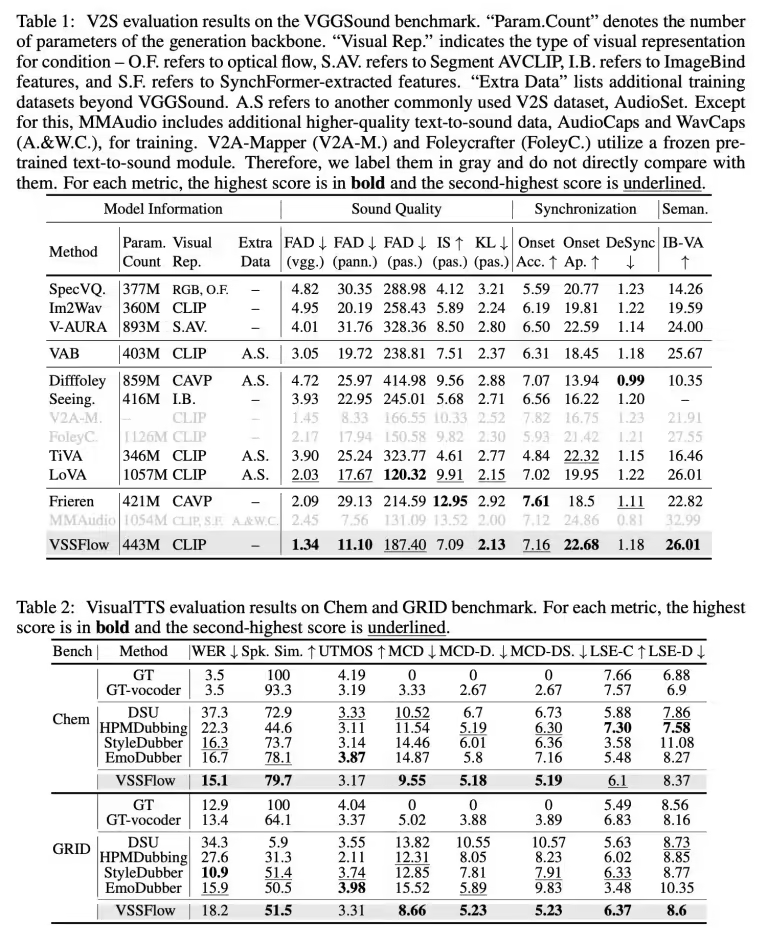
据ITCOW牛新网了解,模型以每秒10帧频率提取视频视觉特征生成环境音效,同时根据文本脚本精准控制语音输出。测试数据显示,其在多项关键指标上超越专注于单一任务的竞品模型。研究团队已在GitHub平台开源VSSFlow代码,并正推进模型权重公开与在线演示开发。