ITCOW牛新网 3月2日消息,阿里通义实验室语音团队今日发布两款支持“FreeStyle”指令生成的语音大模型:Fun-CosyVoice3.5 与 Fun-AudioGen-VD。这两款模型打破了传统语音生成对预设标签的依赖,实现了通过自然语言指令进行多语种复刻、精细化表达控制以及场景化音频生成。
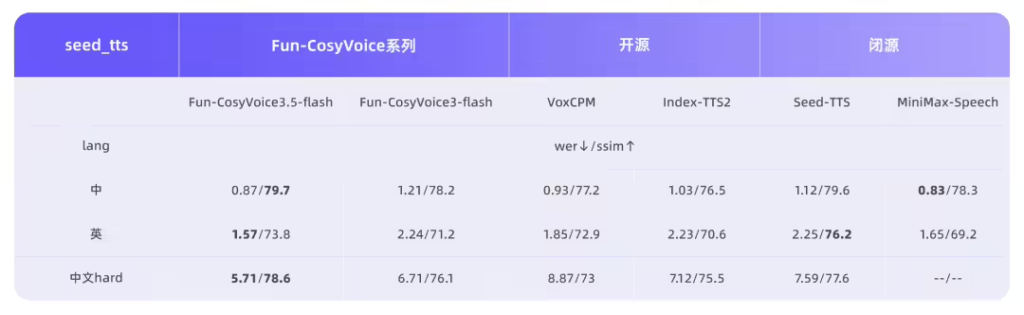
据ITCOW牛新网了解,Fun-CosyVoice3.5 主打多语种复刻与精细化表达控制。该模型支持 FreeStyle 指令控制,用户可以通过自然语言描述(例如“语气坚定一点”、“稍微压低音调,语速慢一点”)来生成所需的语音风格,不再受限于固定的情绪或语气选项。此外,该模型新增了泰语、印尼语、葡萄牙语、越南语支持,覆盖13种语言,生僻字读错率从15.2%降至5.3%,首包延迟降低35%,实时交互响应更快。
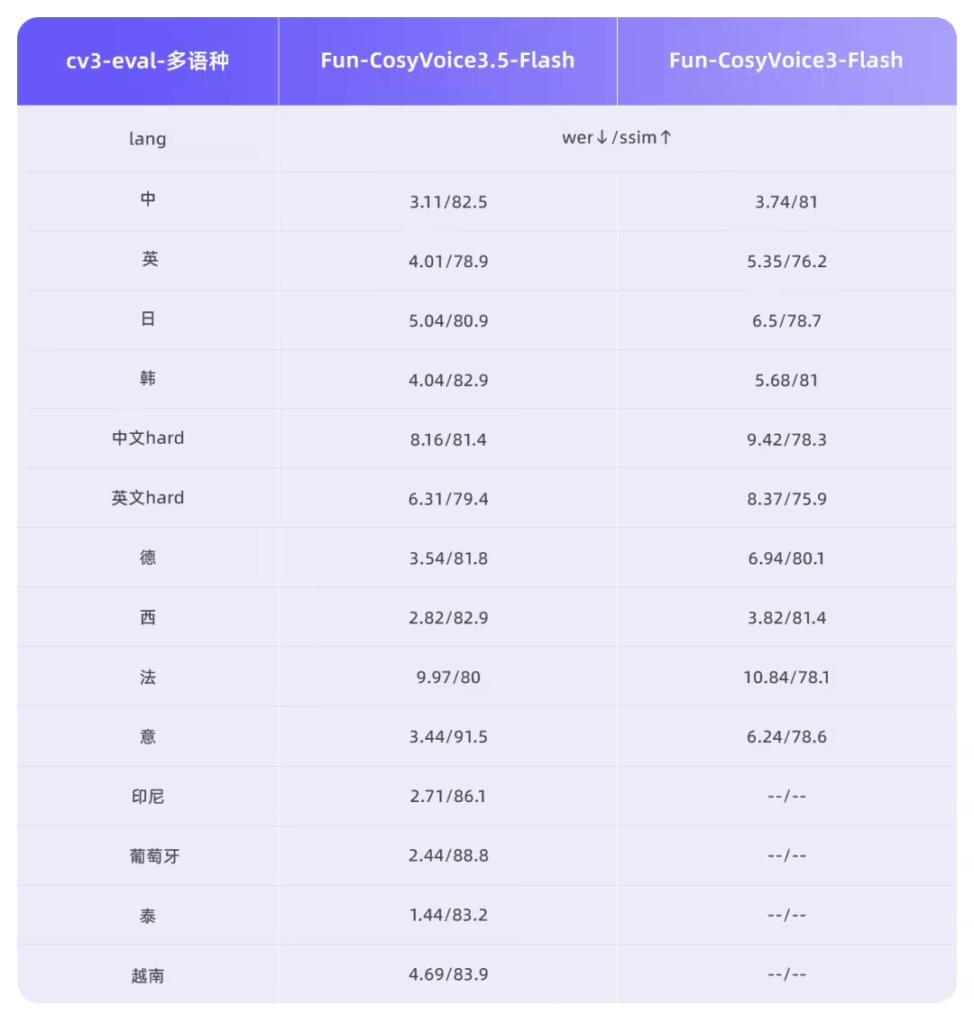
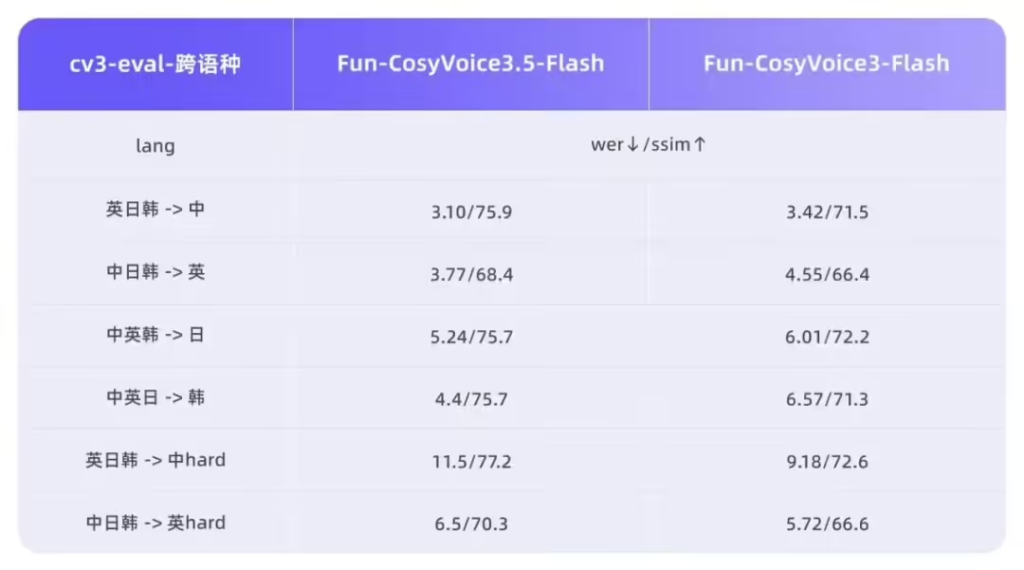
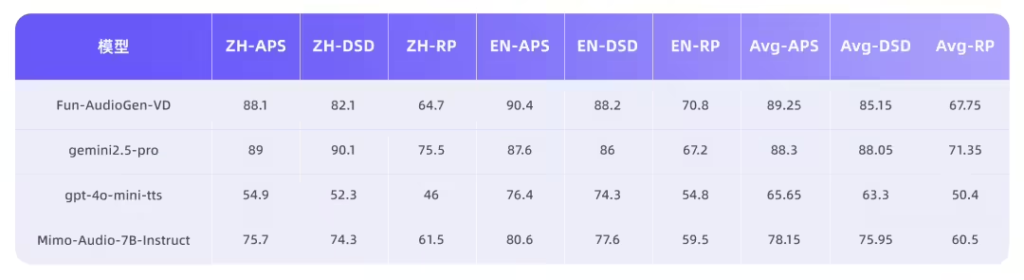
Fun-AudioGen-VD 则专注于声音设计与场景化建模。该模型支持通过指令精确控制性别、年龄、情绪及空间声学效果,能够模拟从“疯狂反派”到“热闹咖啡馆”等复杂的角色与背景音一体化场景。它不仅支持生成“表面镇定但内心颤抖”的复杂心理状态语音,还能叠加背景环境音、空间混响、设备滤镜,打造沉浸式听觉场景。
这两款模型的发布标志着语音生成技术从依赖预设标签的传统范式,向基于自然语言指令自由控制的新范式跨越,将直接赋能影视、游戏及AI智能体等领域。