ITCOW牛新网 3月30日消息,阿里云通义千问(Qwen)今晚发布了新一代全模态大模型 Qwen3.5-Omni。该模型在音频、视频理解及实时交互能力上实现重大突破,官方数据显示其在多项基准测试中超越 Google Gemini 3.1 Pro,并已通过阿里云百炼平台开放 API 调用。
核心能力:视听全能与代码涌现
Qwen3.5-Omni 主打真正的“全模态”原生能力,不仅能处理文本和图像,更能深度理解音频与视频内容:
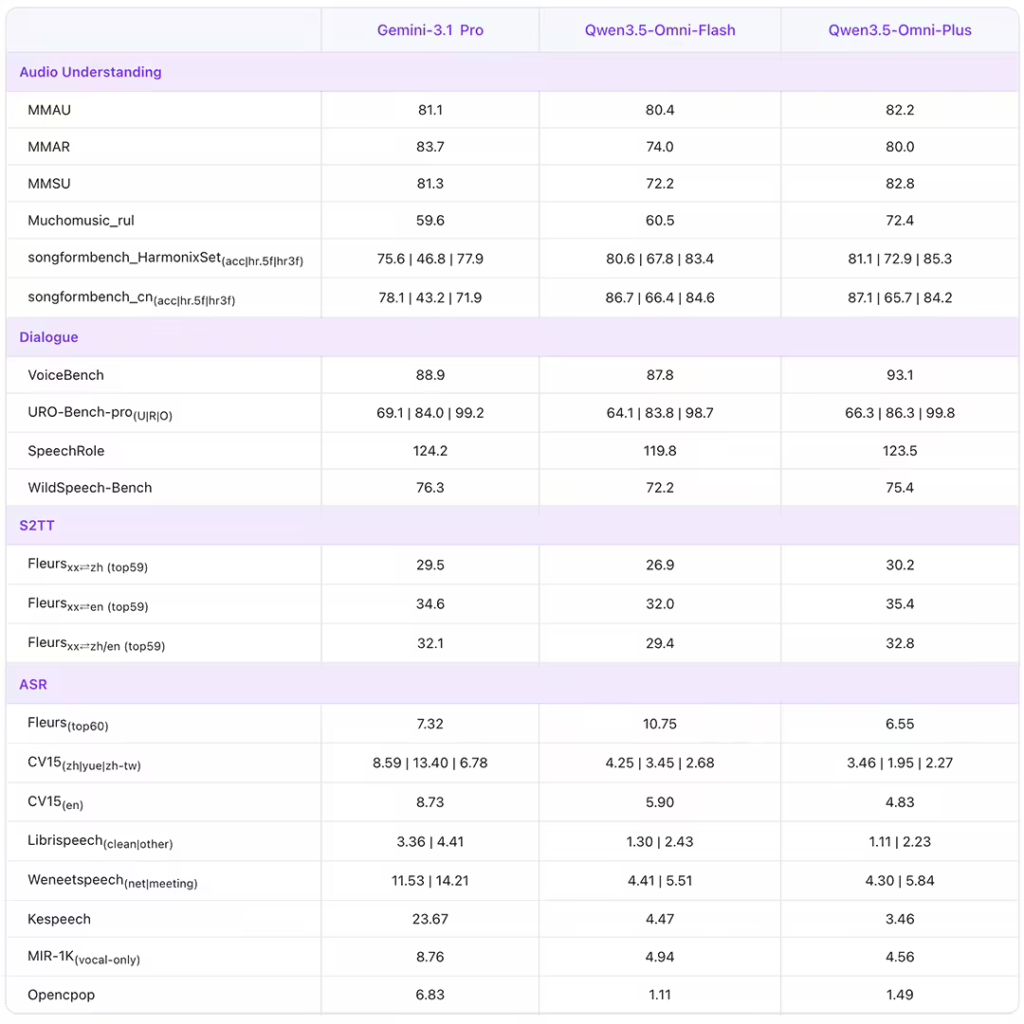
- 音视频理解:支持上传长达 10 小时的音频或 1 小时视频,可生成带精确时间戳的结构化摘要(Caption),自动识别画面人物、对话内容、镜头切换及背景音乐变化,将长视频转化为可搜索的“结构化笔记”。
- Audio-Visual Vibe Coding:模型展现出“自然涌现”的编程能力。用户输入音视频指令,模型可直接生成可运行的 Python 代码或前端网页原型,实现从“看到”到“做到”的快速验证。
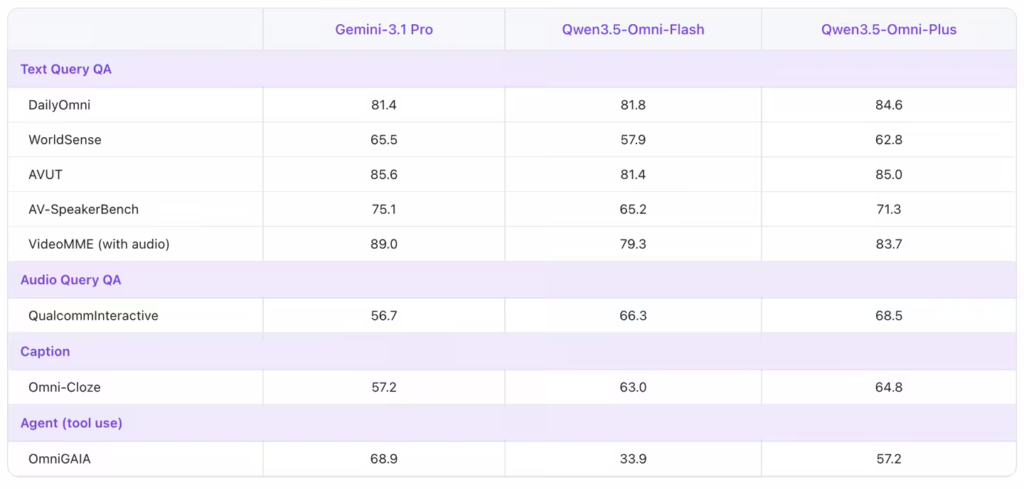
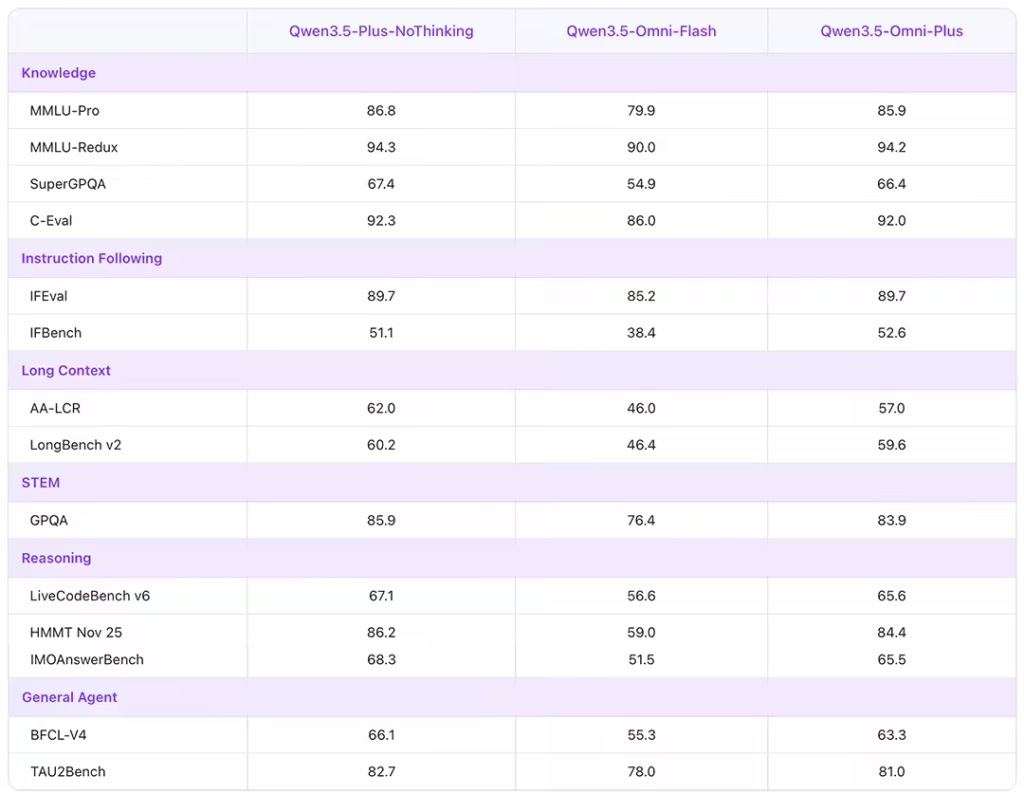
- 性能对标:在音频理解、推理、翻译等 215 项任务中取得 SOTA(当前最佳)成绩,官方宣称全面超越 Gemini 3.1 Pro。
交互体验:真人级对话与音色克隆
相比前代,新模型在“像人一样交流”的体验上大幅优化:
- 语义打断与语音控制:支持智能语义打断,能区分咳嗽声(不打断)与真实插话(瞬间接住)。用户可通过语音指令实时控制 AI 的语速、音量及情绪(如“小声点”、“用开心的语气”)。
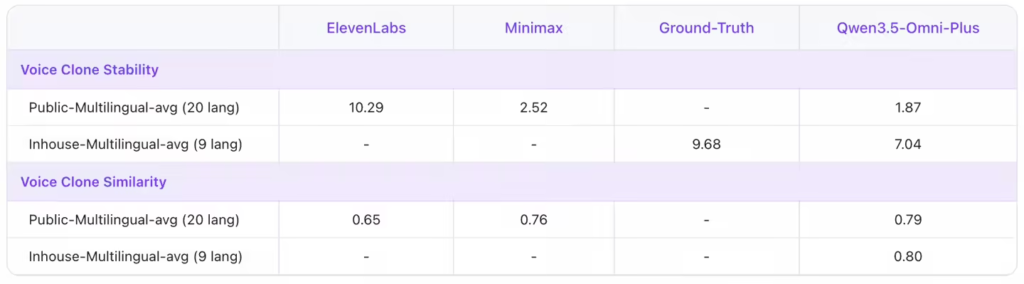
- 音色克隆:用户上传一段录音即可定制专属音色,打造“数字分身”助手,支持多语言生成。
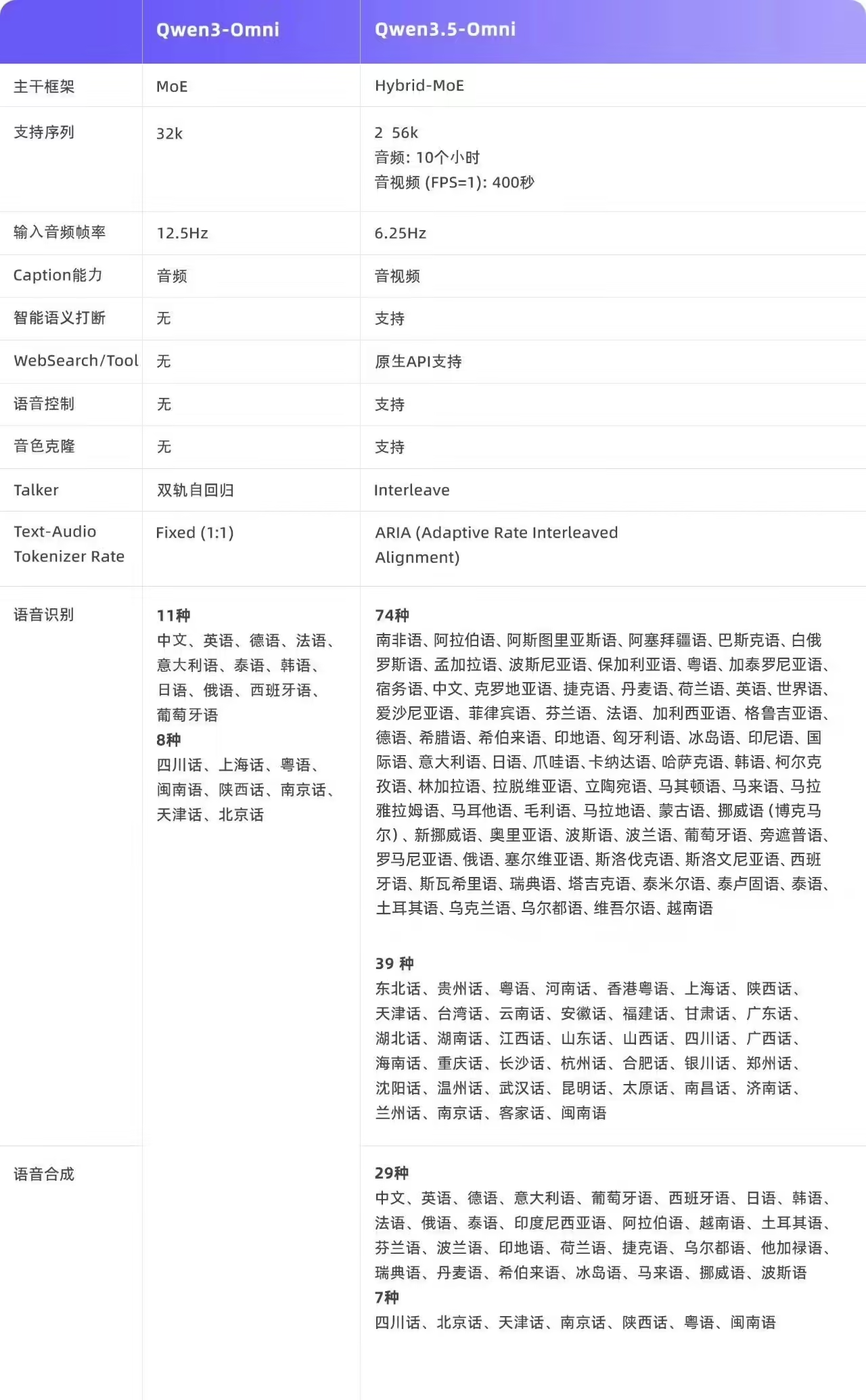
- 长上下文与多语言:支持 256K 超长上下文,识别 113 种语言,并原生集成 WebSearch 联网搜索与 Function Call 工具调用能力。
技术架构与获取方式
- 架构升级:延续 Thinker(理解)- Talker(表达)双模块设计,升级为 Hybrid-Attention MoE 架构,配合 ARIA 技术解决语音漏字、错读问题。
- 模型版本:提供 Plus(最强能力)、Flash(均衡)、Light(轻量)三种尺寸。
- 平台上线:目前已上线阿里云百炼平台,开发者可通过 API 调用,普通用户也可在 Qwen Chat 等渠道体验。