ITCOW牛新网 6月22日消息,百川智能联合清华大学研究团队于今日推出新一代医疗增强大模型——Baichuan-M4。该模型在 OpenAI 提出的医疗评测基准 HealthBench 及其 Hard(高难度)、Professional(专业临床)两个子榜单上同时斩获全球第一,综合表现全面超越 GPT-5.5、Claude Opus 4.7 及 DeepSeek-V4-Pro,幻觉率低至 3.3%,标志着国产垂类大模型在严肃医疗场景中的能力突破。
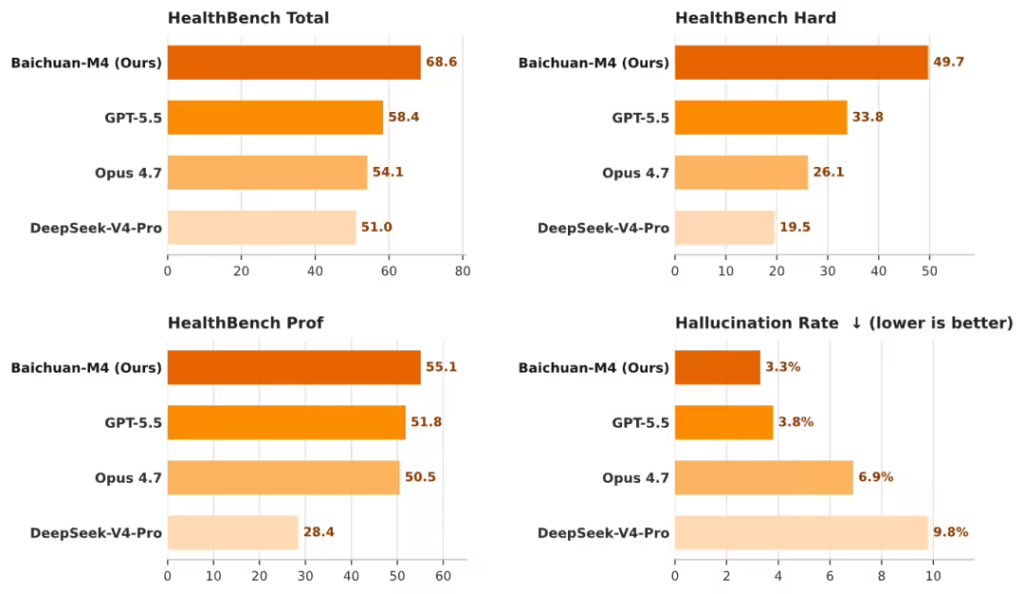
具体来看,Baichuan-M4 在 HealthBench 综合得分达 68.6,领先第二名 GPT-5.5 超过 10 分;在最考验复杂临床决策推理的 Hard 子集上,领先优势扩大至 15.9 分。据ITCOW牛新网了解,百川智能借鉴医学教育中常用的 OSCE(客观结构化临床考试)方法,联合 150 多位一线医生构建了动态多轮问诊评测体系 SCAN-bench,模拟医生从接诊、问诊到确诊的完整过程。在该评测中,M4 初诊得分 79.0、复诊得分 74.7,均明显优于上述国际主流竞品。与被动等待用户输入的模型不同,M4 会主动追问症状性质与诱因,优先识别和排查危急重症,更符合真实诊疗逻辑。
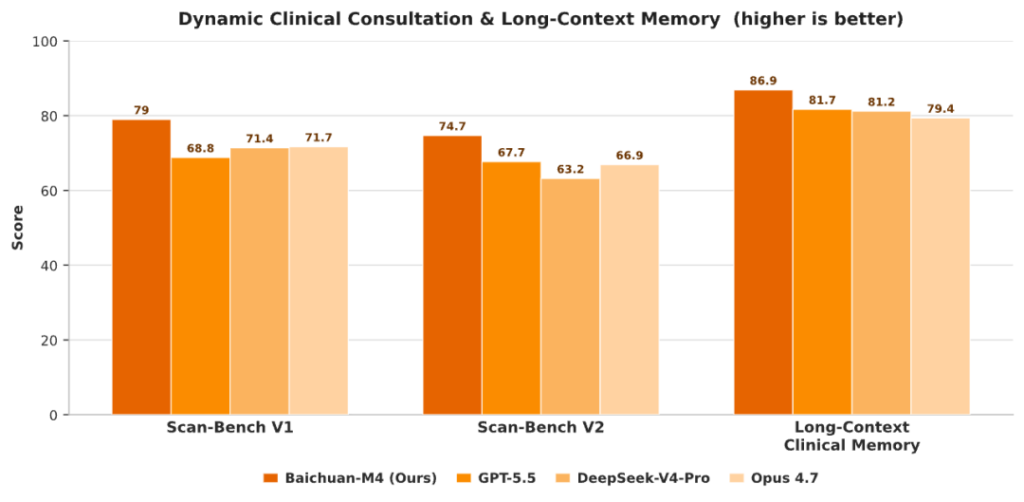
在长时记忆与循证医学能力上,Baichuan-M4 推出了“全病程记忆”机制,可打通历史病历、多轮问诊记录、化验趋势与用药反馈,使模型在跨会话交互中始终掌握患者完整背景,无需每次从零开始复述。长上下文临床记忆评测中 M4 取得 86.9 分,较上一代 M3 提升 21.1 分,为同类最高。同时百川首创”证据锚定”技术,要求模型生成的每一句医学结论都精确对应到原始论文或指南的具体段落,而非仅泛泛标注文献来源;模型仅在权威医学库(六源循证范式)中检索,不抓取整开放网络资料,目前已将覆盖 200 余种疾病的超 1000 条标准化临床路径单元植入系统,每条均由资深临床专家定义校验。在循证引用精度评测 Baichuan-EBM 上,M4 达到 90.0%,大幅高于 GPT-5.5 的 54.7% 和 OpenEvidence 的 55.9%。
百川智能表示,Baichuan-M4 的技术报告已上传至 arXiv(https://arxiv.org/abs/2606.08982),后续将逐步向 certified 医疗机构与科研单位开放 API 试用。随着垂类专业大模型在诊断辅助、问诊分流及循证决策支持等场景的价值被不断验证,国产 AI 医疗赛道正进入以临床实效为核心竞争力的深水区。