ITCOW牛新网 6月25日消息,百度公司于6月22日在开源社区推出 Unlimited OCR 大模型,这是一款专为端到端光学字符识别与长文档解析场景设计的视觉语言模型。该模型总参数量达30亿,推理时借助混合专家(MoE)结构仅激活5亿参数,在保持高识别精度的同时显著降低显存占用与延迟,直指传统端到端 OCR 解析多页文档时“KV Cache 膨胀导致越生成越慢”的行业痛点。
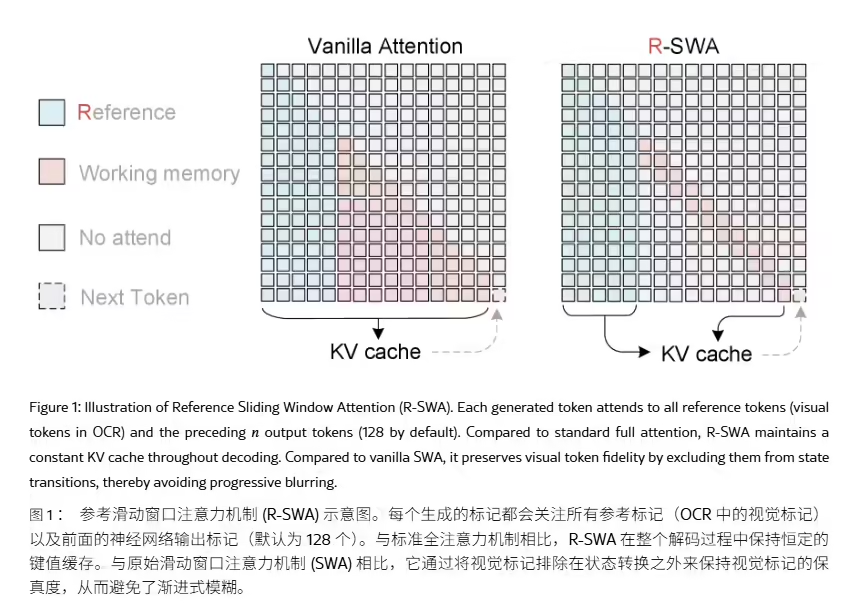
端到端 OCR 摒弃了传统“先检测文本框、再逐个识别”的两阶段流程,直接用统一神经网络将图像映射为文本序列,减少了信息丢失。但主流方案每生成一个 Token 都会扩大键值缓存(KV Cache),文档页数越多、预填充阶段越长,显存压力与推理延迟便同步攀升,用户感知为“越跑越卡”。据ITCOW牛新网了解,Unlimited OCR 延续 DeepSeek OCR 的 DeepEncoder + MoE Decoder 架构,编码端采用两级视觉编码并在连接层执行16倍 Token 压缩——一张1024×1024分辨率的 PDF 页面图像仅需256个视觉 Token 即可表征,从源头减轻了预填充的计算与存储负担。
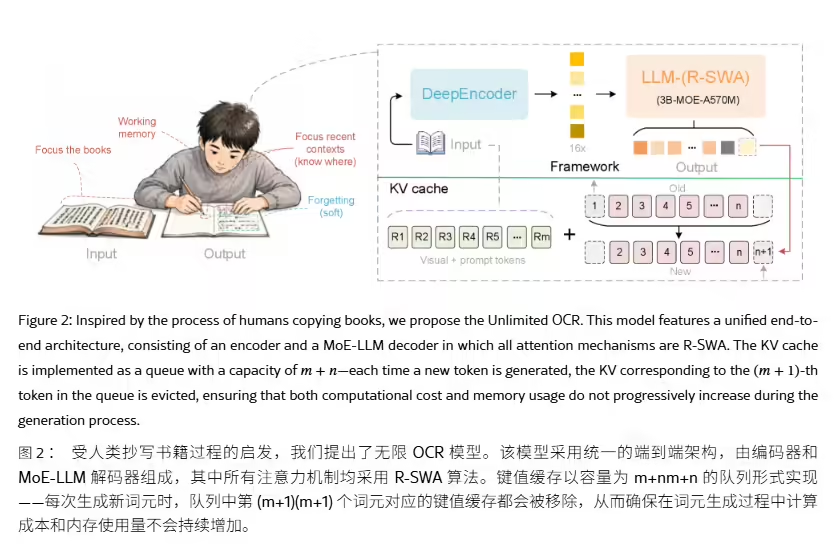
训练策略上,百度以 DeepSeek OCR 检查点为基底继续训练4000步,冻结 DeepEncoder 仅微调 MoE 解码器部分,所用约200万份文档样本中单页与多页比例约为9:1(多页样本通过拼接构造),全程运行于8×16张 A800 GPU 集群。基准测试结果显示,Unlimited OCR 在 OmniDocBench v1.5 上整体得分93.23(DeepSeek OCR 为87.01,DeepSeek OCR 2 为89.17),文本编辑距离0.038、公式 CDM 92.61、表格 TEDS 90.93、读序编辑距离0.045;在更新的 v1.6 基准上总分进一步达93.92,全面超越原版 DeepSeek OCR 系列。
百度已将 Unlimited OCR 模型权重与推理示例代码公开,开发者可在主流开源框架中直接调用或做二次微调,适用于合同批量解析、古籍数字化、多栏论文抽取等对长文档吞吐量敏感的垂直场景。这也是国内头部大厂首次基于 DeepSeek OCR 架构进行针对性工程改良并回馈开源社区,为文档智能处理赛道提供了更具性价比的国产化选项。