ITCOW牛新网 5月22日消息,美团技术团队今日开源了其数字人视频生成模型 LongCat-Video-Avatar 1.5。此次发布的版本在唇形同步、物理合理性、长视频稳定性以及多人互动等方面进行了全面升级,标志着该模型从追求“高拟真”的开源SOTA(当前最佳)水平正式迈向了“真可用”的商业级应用阶段,旨在解决数字人技术在复杂商业场景中的落地难题。

据ITCOW牛新网了解,该版本在基础体验上进行了深度优化,能够从容应对长句、快语速甚至歌唱等复杂语音输入,确保唇部运动精准平滑,同时让面部表情、头部姿态与肢体动作更加协调自然。在场景支持方面,得益于高质量的数据体系,模型不仅能稳定处理真人、动漫、动物等多种主体,还能在多人对话场景中精准区分说话者与聆听者,极大地拓展了应用边界。此外,通过采用DMD蒸馏技术,模型的推理步数从50步大幅压缩至8步,推理效率提升了约15倍,生成一段10秒的视频仅需约1分钟,显著降低了规模化应用的成本。

从技术架构来看,1.5版本主要实现了三大核心升级。首先是音频特征提取编码器的迭代,从Wav2Vec2升级为参数量更大、多语言先验更丰富的Whisper-large,从而更细致地捕捉音素变化,减少长视频中的抖动与身份漂移。其次是构建了包含离线标注和在线验证的多阶段数据处理流程,并专门增加了多人、静默及情绪三类增强数据,以应对虚拟人生成的典型难点。最后是通过逐帧级的GRPO(组相对策略优化)偏好对齐技术,针对手部稳定性和动作连续性进行了专项优化,有效缓解了手部畸变和动作不连贯等行业痛点。
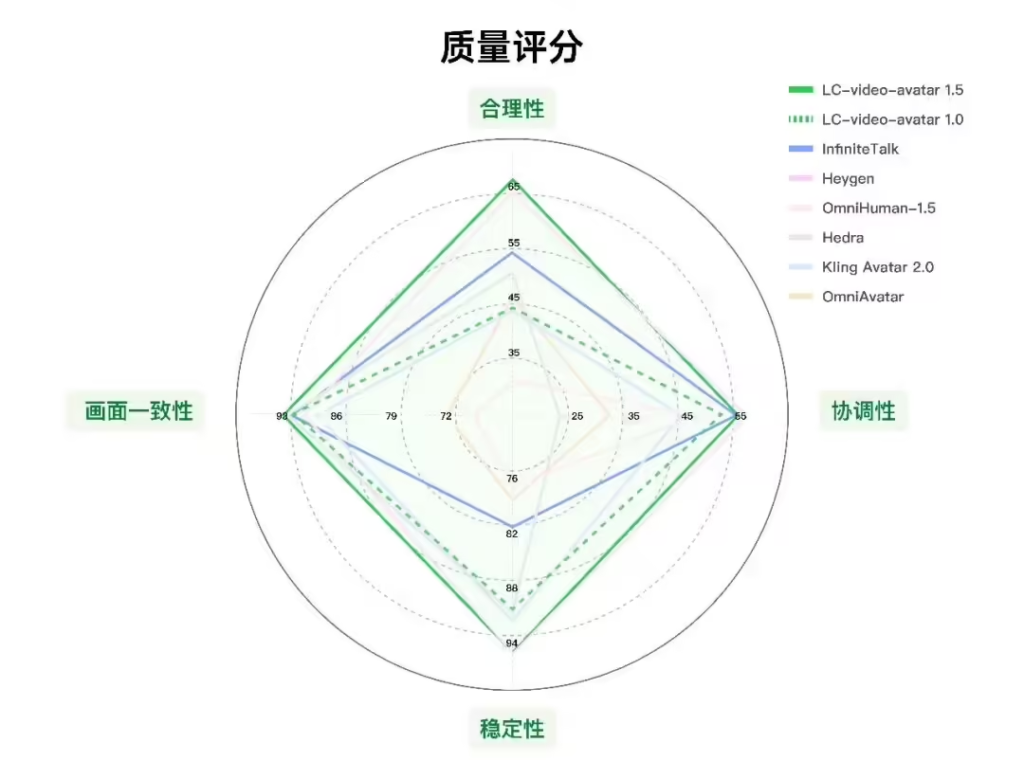
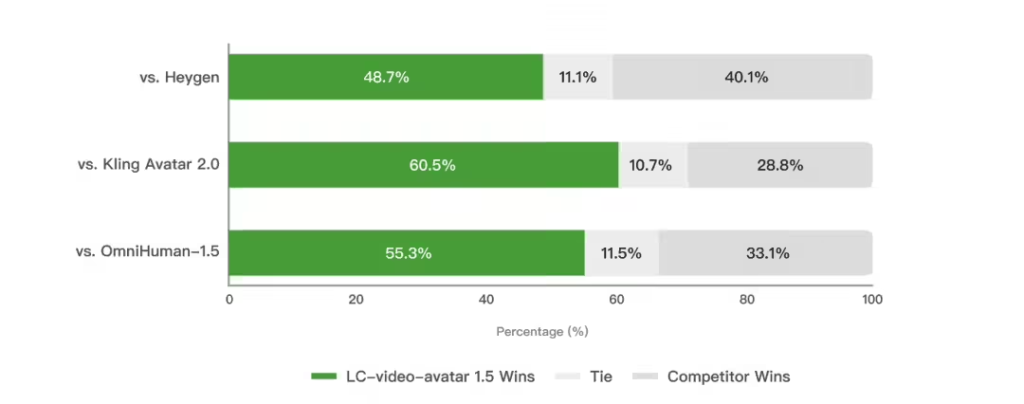
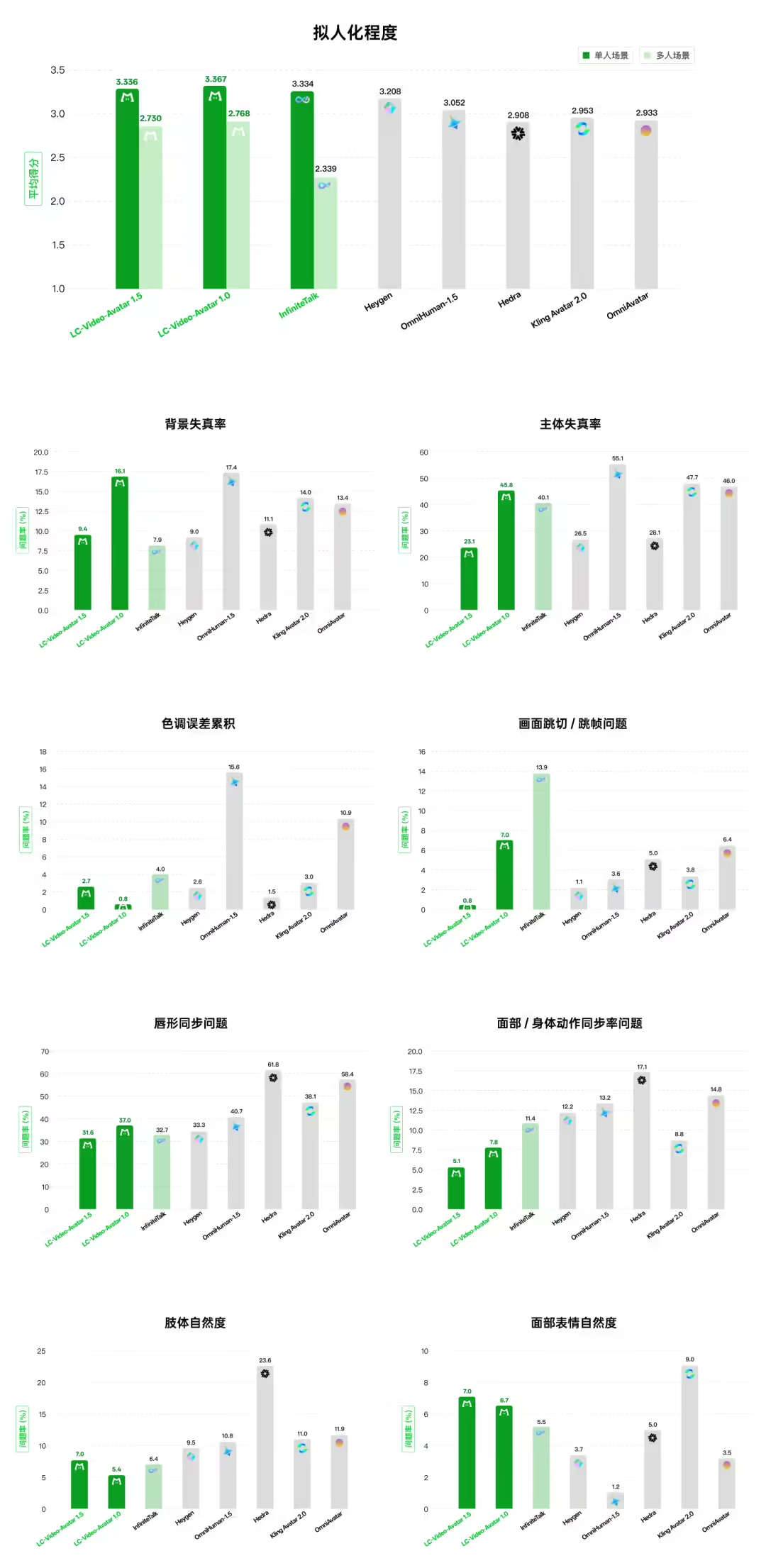
在性能评测环节,美团基于EvalTalker构建了覆盖新闻、教育、娱乐等场景的综合基准。由770名评估者和10名专家完成的测试显示,在物理合理性、时间稳定性等四个核心维度上,LongCat-Video-Avatar 1.5均处于领先水平。在用户偏好对比中,该模型相比Kling Avatar 2.0胜率达65.9%,相比OmniHuman-1.5胜率为61.1%,相比HeyGen胜率为54.3%。特别是在多人场景中,其得分大幅领先InfiniteTalk,且主体变形率仅为23.1%,跳帧问题率低至0.8%,表现优于多数对比模型。美团方面表示,希望此次开源能成为一个可验证、可改进的技术基座,邀请全球开发者和创作者共同探索数字人视频的真实应用边界。
开源地址:
- Github: https://github.com/meituan-longcat/LongCat-Video
- HuggingFace: https://huggingface.co/meituan-longcat/LongCat-Video-Avatar-1.5
- 技术报告: https://github.com/meituan-longcat/LongCat-Video/blob/main/assets/LongCat-Video-Avatar-1.5-Tech-Report.pdf
- 项目主页: https://meigen-ai.github.io/LongCat-Video-Avatar-1.5-Page/
- ModelScope: https://www.modelscope.cn/models/meituan-longcat/LongCat-Video-Avatar-1.5/summary