ITCOW牛新网 5月28日消息,英伟达研究团队于本周发布了名为Polar的开源框架。这一创新工具旨在解决现有智能体框架难以接入强化学习训练的痛点,它允许Codex、Claude Code、Qwen Code等主流代码智能体,在不破坏原有工具调用、上下文组织和补丁提交流程的前提下,顺利接入GRPO(广义相对策略优化)训练体系。GRPO作为一种面向强化学习的优化方法,通过奖励信号调整模型策略,使模型在多步决策任务中学会更优动作,特别适用于代码仓库修改、浏览器操作等长流程复杂任务。


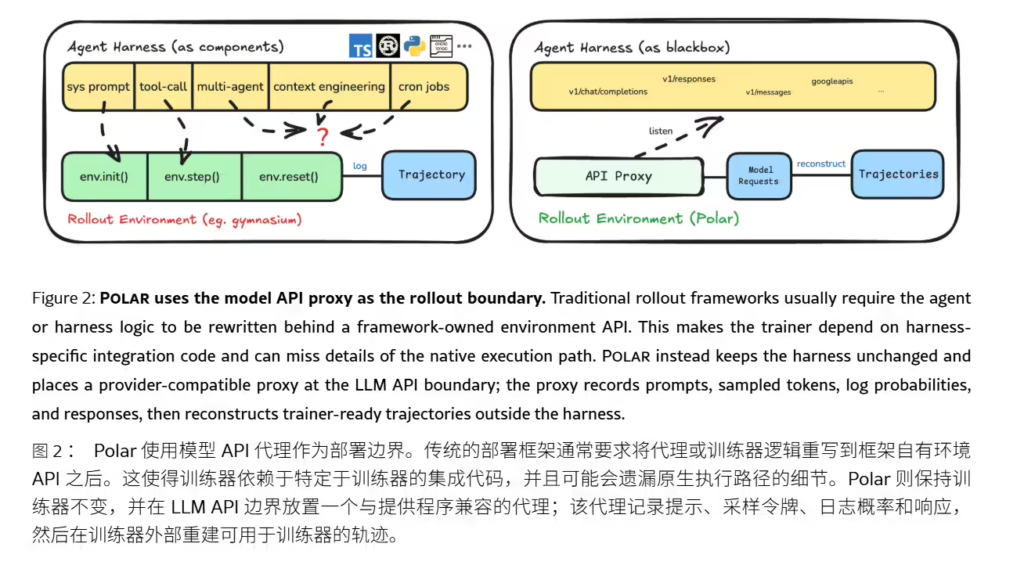
据ITCOW牛新网了解,传统方法在将智能体执行框架接入强化学习环境时面临巨大挑战,往往需要强行改写代码逻辑以适配标准接口,这不仅成本高昂,还极易丢失关键的原生执行细节。Polar框架则另辟蹊径,它并未选择重写智能体框架,而是将模型API边界作为训练边界。具体而言,该框架在执行框架和推理服务器之间放置了一个模型智能体,兼容Anthropic、OpenAI、Google等风格的API请求。这个代理在转发请求的同时,会忠实记录提示词、采样Token、对数概率及响应内容,并在外部重建成可供训练器消费的轨迹,从而完整保留了原生执行路径的细节。
在系统架构上,Polar由rollout server(部署服务器)和gateway node(网关节点)两大核心组件构成。前者负责任务提交、会话调度、状态持久化及回调接收;后者则管理会话执行的全生命周期,包括运行时启动、执行框架准备、轨迹构建、结果评测和资源回收。为了进一步提升效率,Polar将初始化、运行中、后处理流程拆分到独立工作池,并设置READY缓冲区,让运行时预热和评测预热能在后台并行执行,有效减少了长尾任务对GPU训练的阻塞。
从实际效果来看,Polar配合GRPO训练带来了惊人的性能提升。基于Qwen3.5-4B底座模型,在SWE-Bench Verified测试中,Codex的pass@1分数从3.8%跃升至26.4%,增长幅度高达594.74%;Claude Code从29.8%提升至34.6%;Qwen Code从34.6%提升至35.2%;Pi框架从34.2%提升至40.4%。在训练效率方面,Polar引入的prefix_merging技术表现卓越,相比传统方法,它将3个训练步骤的更新次数从1185次降至218次,墙钟时间从189.5分钟大幅缩短至35.2分钟,速度提升约5.39倍,同时将rollout GPU的平均利用率从20.4%拉升到了87.7%。