ITCOW牛新网 5月29日消息,Anthropic 今日正式发布了其旗舰大语言模型的最新迭代版本——Claude Opus 4.8。此次更新并未单纯追求参数规模的扩张,而是将重心放在了提升模型在复杂智能体任务中的可靠性、代码生成的准确性以及输出的“诚实度”上。官方强调,Opus 4.8 在处理多步骤复杂任务时表现得更加稳健,具备更强的主动纠错能力,能够在发现计划不合理时提出异议,而非盲目执行。
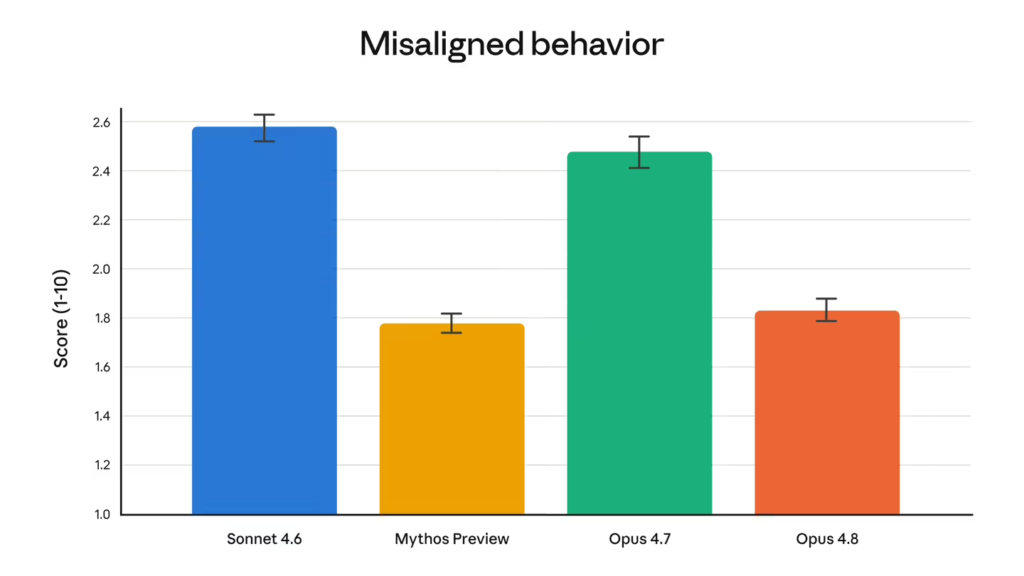
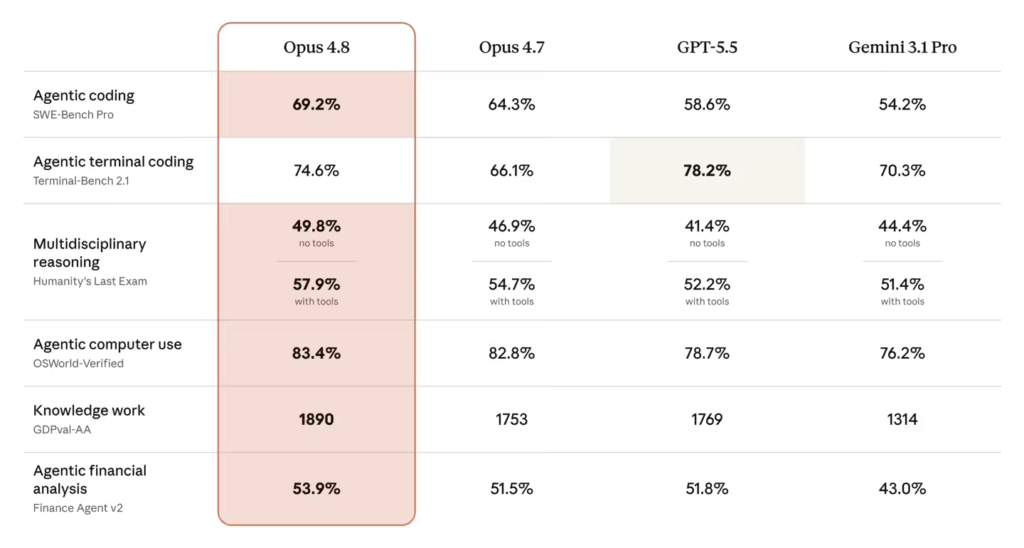
据ITCOW牛新网了解,Opus 4.8 在多项权威基准测试中展现了强劲的竞争力。在软件工程基准测试 SWE-Bench Pro 中,该模型取得了 69.2% 的得分,成功超越了其竞争对手 GPT-5.5 和 Gemini 3.1 Pro。特别是在代码缺陷识别和复杂逻辑推理方面,新模型表现出更高的敏锐度。不过,在特定的终端编程基准测试中,GPT-5.5 依然保持着微弱的优势。除了性能的提升,Anthropic 还特别优化了模型的“对齐”表现,Opus 4.8 在支持用户自主性和维护用户利益等亲社会指标上创下新高,同时大幅减少了欺骗性输出,其表现已接近此前备受好评的 Claude Mythos Preview 模型。
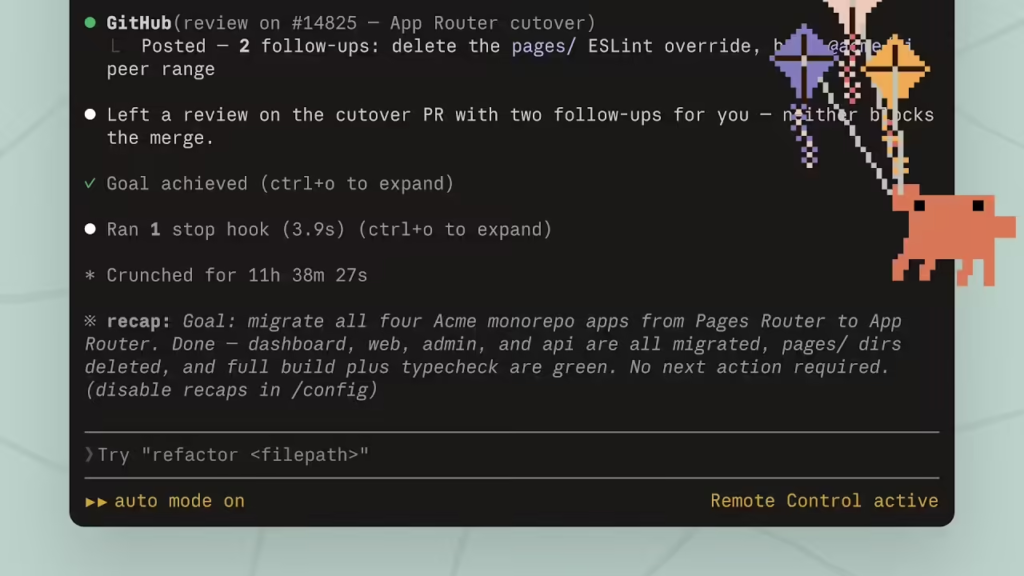
在用户体验与定价策略方面,Anthropic 带来了颇具诚意的调整。Opus 4.8 引入了全新的“Effort 程度控制”功能,允许用户根据任务难度在 claude.ai 界面中手动平衡回复质量与响应速度。默认开启的“High”档位在编码任务中能提供优于前代的体验,而追求极致结果的专业用户则可以选择消耗更多算力资源的“Max”档位。
更为关键的是,新模型的快速模式(Fast Mode)推理速度提升至原来的 2.5 倍,而成本却降至此前模型的 1/3。具体定价上,常规模式维持每百万输入令牌 5 美元、输出 25 美元不变;快速模式则定为输入 10 美元、输出 50 美元。这一“加量减价”的策略无疑将降低开发者部署高性能 AI 应用的门槛,进一步推动智能体编程的普及。