ITCOW牛新网 4月24日消息,小米今日正式推出 MiMo-V2.5 全链路语音模型系列,包含 MiMo-V2.5-TTS Series(语音合成)与 MiMo-V2.5-ASR(语音识别)。该系列主打“用自然语言调度声音”,旨在为 Agent(智能体)提供从输入到输出的完整语音交互能力。在商业化策略上,小米采取了激进的开源与免费策略:TTS 系列在 MiMo 开放平台限时免费,ASR 模型则直接开源了权重与代码。

语音合成(TTS):像导演一样控制声音
MiMo-V2.5-TTS 系列包含三款模型,均支持通过自然语言指令(如“语速加快、带点悲伤情绪”)或音频标签来精细控制声音输出,无需依赖传统的结构化参数。
- MiMo-V2.5-TTS(基础版):内置多款精品音色,开箱即用,适合通用场景。
- MiMo-V2.5-TTS-VoiceDesign(音色设计):通过一句话描述(如“元气少女音”或“低沉老年音”)从零生成全新音色,无需参考音频。
- MiMo-V2.5-TTS-VoiceClone(音色克隆):仅需数秒至 30 秒的参考音频,即可高保真复刻真人音色,并保留语速、情绪等控制能力。
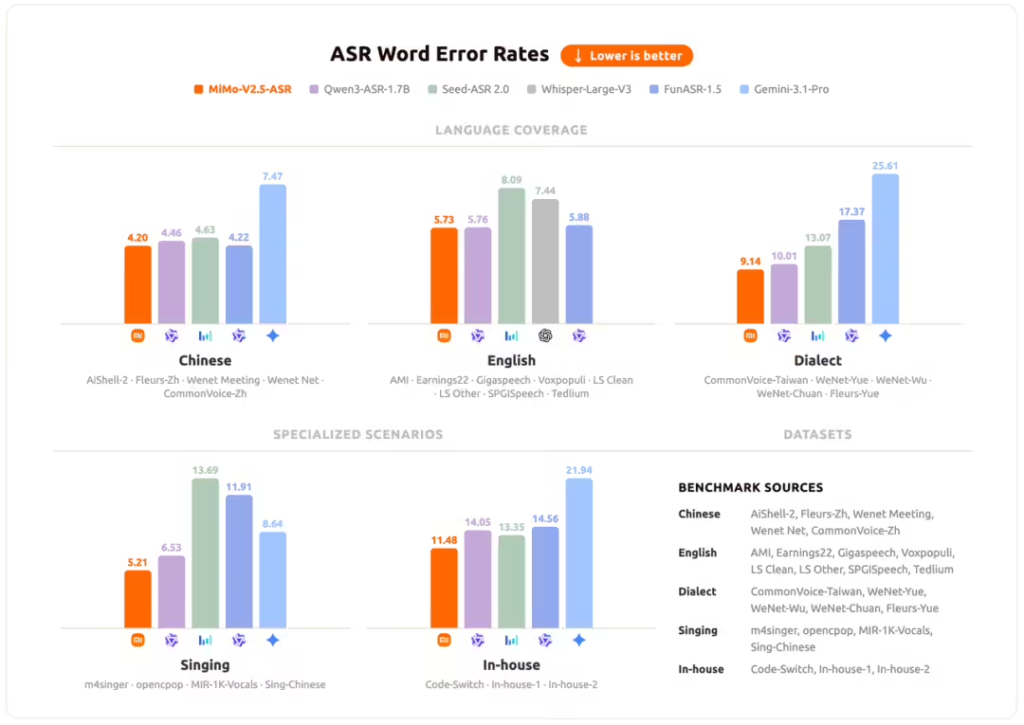
语音识别(ASR):复杂场景的听觉基座
MiMo-V2.5-ASR 作为听觉基座正式开源,其核心优势在于对复杂真实场景的鲁棒性,解决了中英混杂、方言、噪音等传统痛点。
- 多语种与方言:支持中英双语、吴语、粤语、闽南语、四川话等,中英混说(Code-Switch)无需预设语种标签。
- 抗噪与多场景:在强噪音、远场拾音、多人会议及带伴奏的歌曲歌词识别场景下表现领先。
- 智能后处理:结合韵律与语义原生输出标点符号,转写结果无需二次加工即可直接使用。
开发者现可通过 Xiaomi MiMo Studio 体验 TTS 效果,或直接获取 ASR 开源代码进行二次开发。