ITCOW牛新网 4月24日消息,深度求索(DeepSeek)今日上午正式上线并开源了DeepSeek-V4 模型预览版。此次发布的核心突破在于将上下文长度提升至100万token(约百万字),并在Agent智能体与推理能力上实现大幅跃升。
双版本规格与性能定位
DeepSeek-V4 提供了两个不同定位的模型版本,均原生支持 1M 超长上下文:
| 模型版本 | 总参数 | 激活参数 | 核心定位 |
|---|---|---|---|
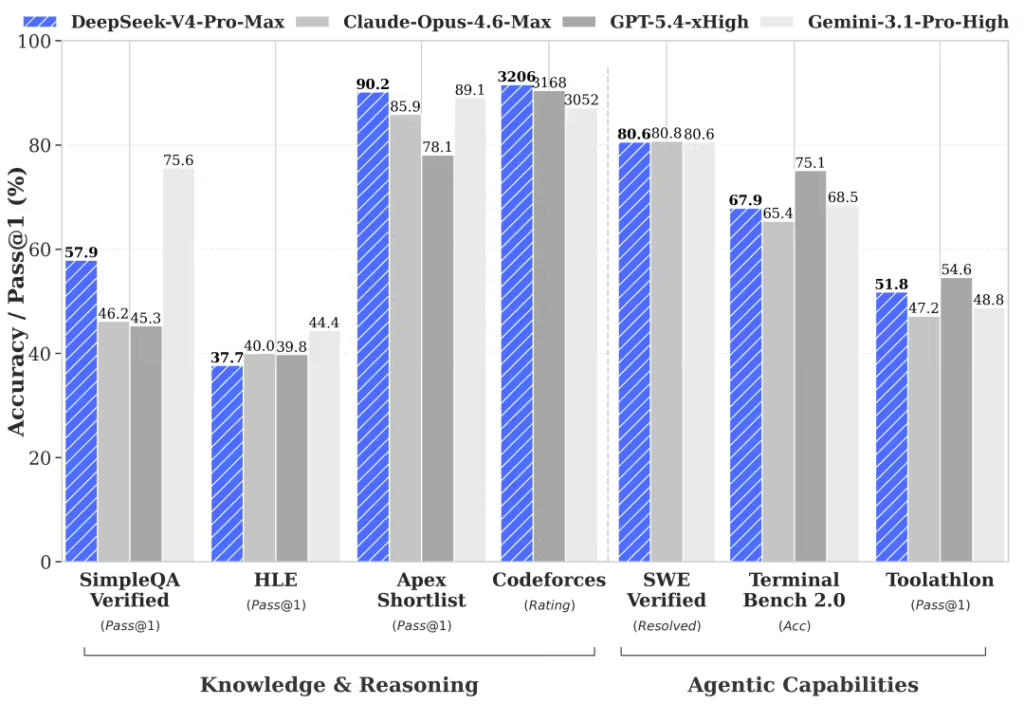
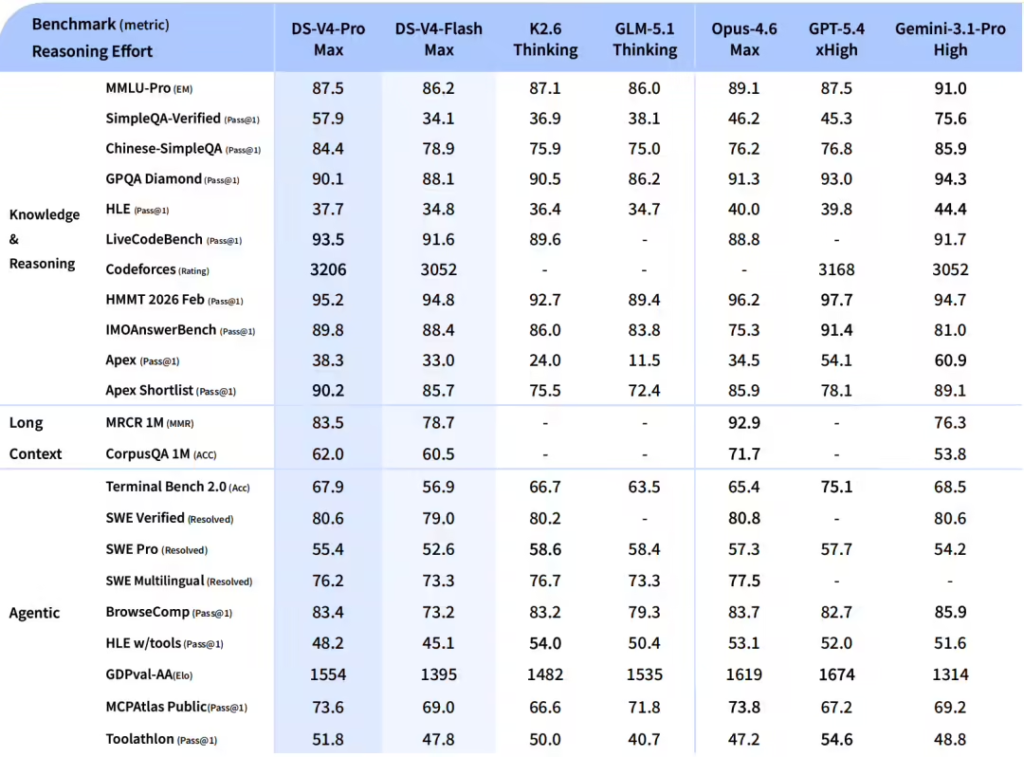
| DeepSeek-V4-Pro | 1.6T (万亿) | 49B (亿) | 性能旗舰。在数学、STEM、竞赛代码及Agent评测中,达到开源领域最佳水平,性能比肩顶级闭源模型。 |
| DeepSeek-V4-Flash | 284B | 13B | 效率优选。主打高性价比与低延迟,在简单任务上推理能力接近Pro版,成本显著降低。 |
技术突破:长上下文与成本优化
- 百万字记忆:1M 上下文能力使其能够一次性处理超长文档(如整本《三体》)、复杂代码库或长程对话历史,打破了此前大模型在长文本处理上的瓶颈。
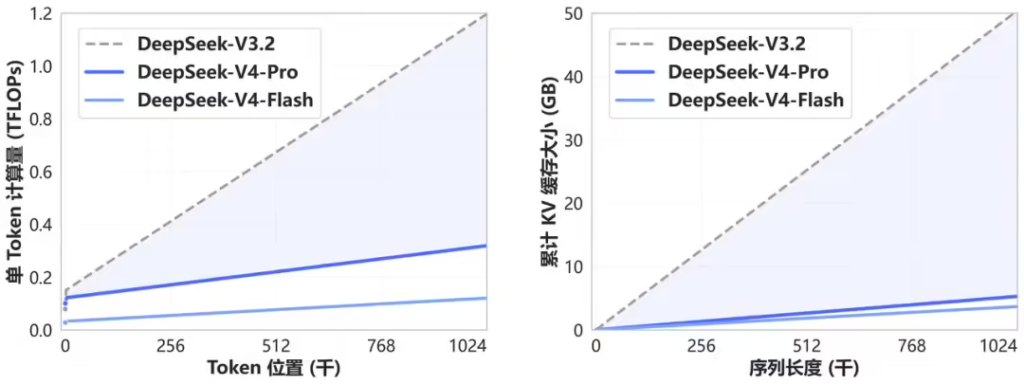
- DSA稀疏注意力:通过创新的注意力机制,在实现长上下文的同时,大幅降低了计算量与显存占用。在1M上下文下,V4-Pro的单token推理FLOPs仅为V3.2的27%,KV Cache降至10%,实现了“更长且更省”的技术突破。
获取方式与API调用
- 立即体验:用户现可登录 DeepSeek 官网 (chat.deepseek.com) 或官方 App 直接使用 DeepSeek-V4 进行对话。
- 开发者接入:API 服务已同步更新,调用时需将
model_name修改为deepseek-v4-pro或deepseek-v4-flash。 - 开源资源:模型权重与技术报告已在 Hugging Face 和 ModelScope 平台开源发布,供开发者下载与研究。
此次发布标志着 DeepSeek 在长上下文推理和智能体能力上进入了全球第一梯队,为开发者和企业提供了更强大的开源基础模型选择。