ITCOW牛新网 4月25日消息,阶跃星辰昨日正式推出了其新一代自动语音识别模型——StepAudio 2.5 ASR。这一模型的最大亮点在于,它率先将原本应用于大语言模型领域的推理加速技术引入到了语音识别赛道,成功打破了传统语音模型在效率与精度上的瓶颈。对于需要高频处理音频数据的会议系统、智能语音助手以及媒体剪辑工具而言,这是一次底层技术的显著升级。

据ITCOW牛新网了解,传统语音识别模型往往受限于“逐字输出”的自回归机制,导致转写速度难以提升。StepAudio 2.5 ASR 创新性地采用了 ASR+MTP-5 深度融合架构,移植了多 Token 预测(MTP)技术。这意味着模型不再是一个字一个字地“挤牙膏”,而是能够一次性预测多个候选词并进行并行验证。实测数据显示,该模型的推理速度飙升了 400%,时延降低了 60%,推理峰值可达 500 tokens/s,而推理成本则直接下降了 80%。
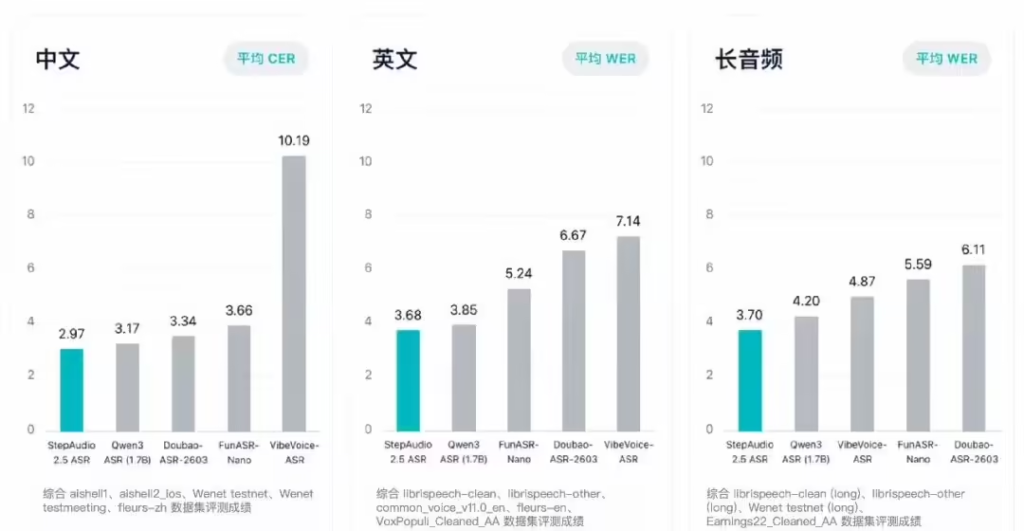
在长音频处理这一行业痛点上,该模型也交出了优异答卷。以往处理长录音时,业界通常依赖“切片-转写-拼接”的笨重方案,极易导致上下文信息割裂,出现“说着说着就忘了开头讲了什么”的精度衰减问题。阶跃星辰通过复用大语言模型原生的 32K 上下文窗口,让 StepAudio 2.5 ASR 能够端到端地一次性读入长达 30 分钟的连续音频,即便在满载测试下,后段的转写精度依然保持稳定,没有出现明显的性能下滑。
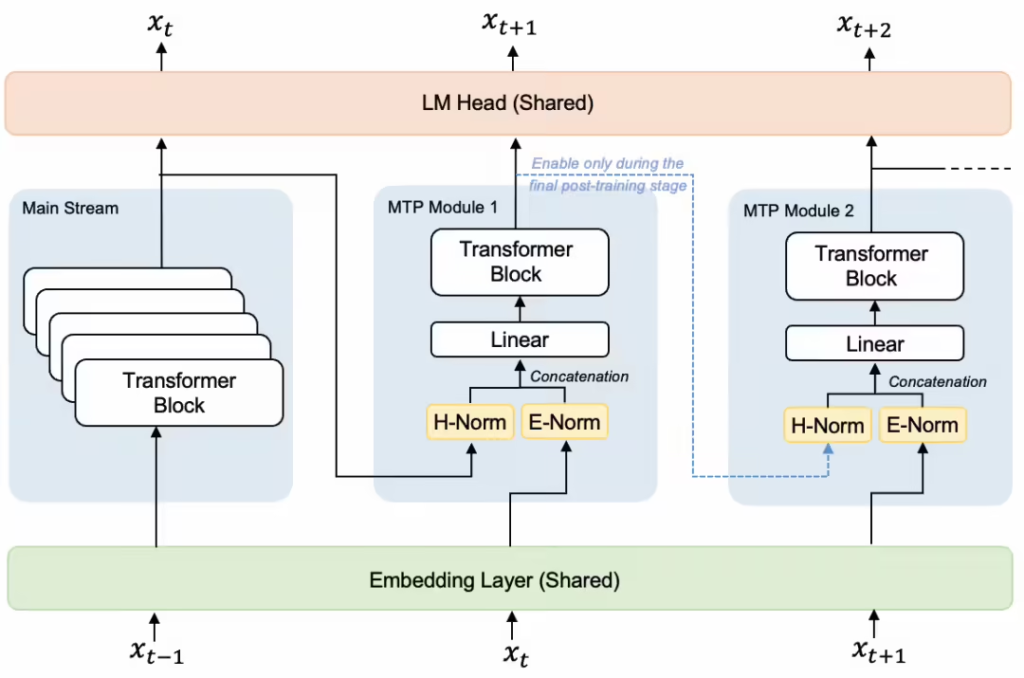
目前,这款在转写精度上达到业内 SOTA(当前最佳)水准的模型,定价仅为 0.15 元/小时,约为其上一代产品的十分之一。该模型现已全量上线阶跃星辰开放平台及 Step Plan,开发者可以直接通过官网接入使用。