ITCOW牛新网 4月16日消息,阶跃星辰今日正式推出新一代语音生成模型 StepAudio 2.5 TTS。该模型最大的突破在于将语境理解能力贯穿语音生成全流程,官方宣称其能让 AI 从机械地“念文本”升级为有感情的“演文本”,大幅降低配音创作门槛。

三大核心能力:从全局氛围到字句细节
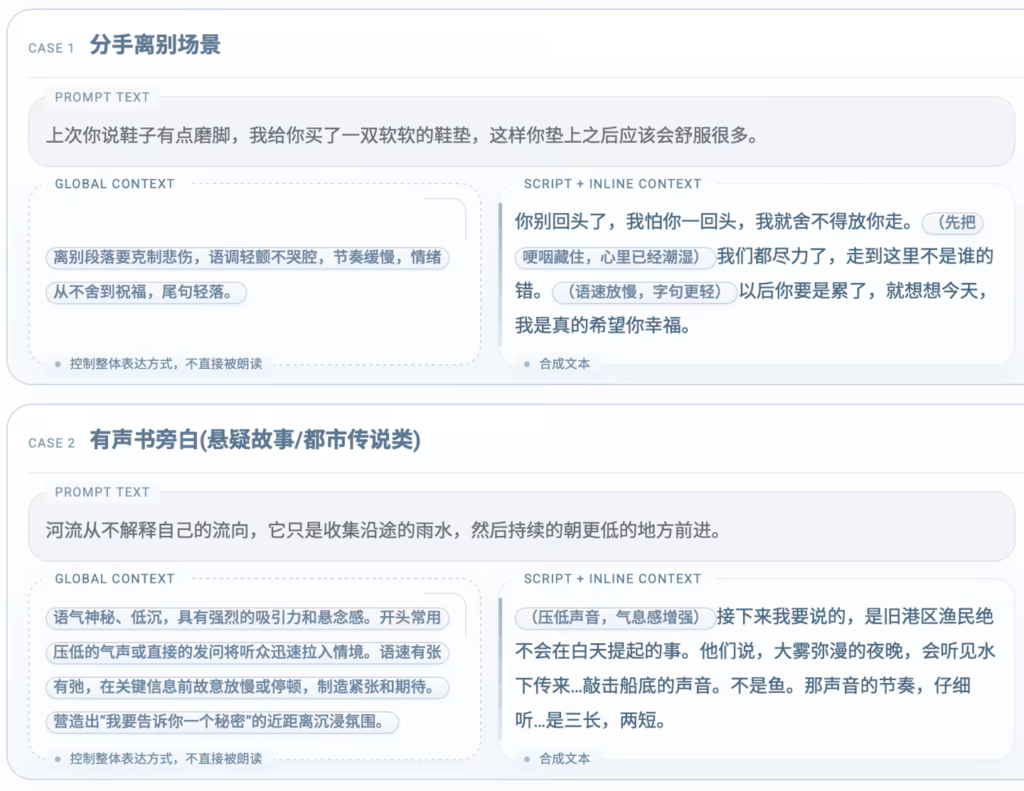
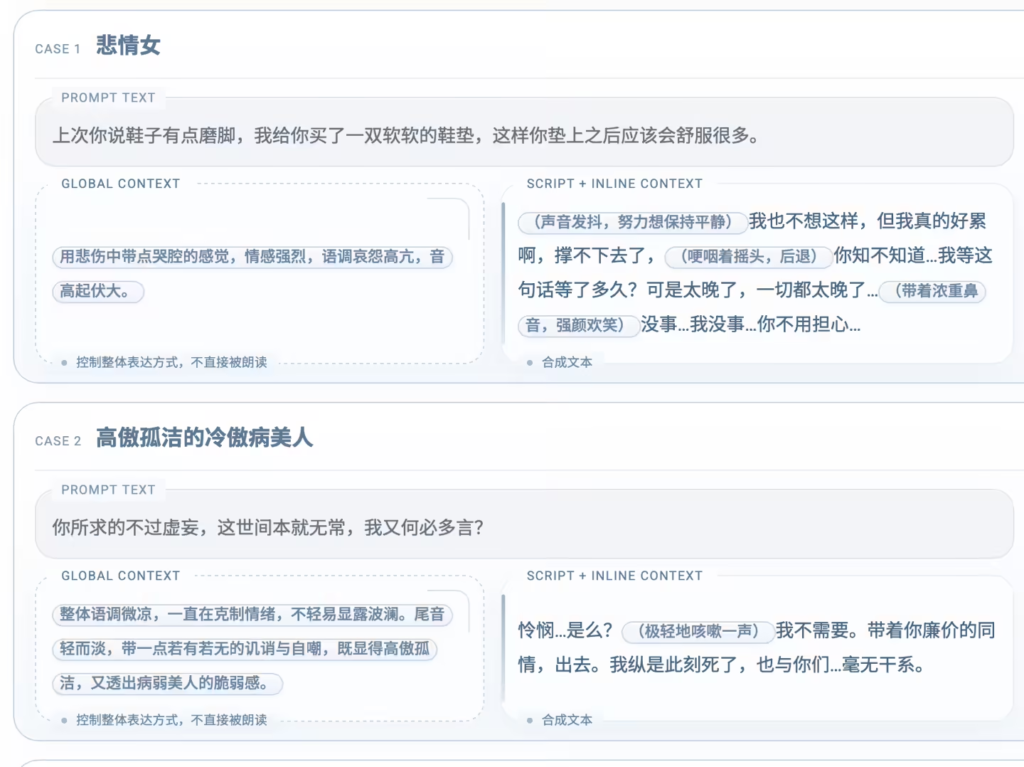
StepAudio 2.5 TTS 引入了“双档语境控制”机制,配合音色复刻技术,实现了对语音输出的精细化操控:
| 能力维度 | 功能解析 | 应用场景举例 |
|---|---|---|
| 全局语境控制 (Global Context) | 设定整段语音的情绪基调、角色状态、场景氛围,确保表达统一连贯。 | 将整段故事基调定义为“深夜电台的温馨陪伴”或“悬疑剧的紧张压抑”。 |
| 文中语境控制 (Inline Context) | 精细化调控语气、节奏、停顿、重音、角色感,实现句级别的情绪转折。 | 在对话中精准插入“迟疑的停顿”、“恍然大悟的语调”或“愤怒的颤音”。 |
| 零样本复刻 (Zero-shot) | 无需训练,仅凭短音频样本即可克隆音色,并独立调节该音色的情感与风格。 | 用同一段克隆音色,分别演绎“冷静的汇报”和“激动的吐槽”。 |
上手体验与获取方式
据ITCOW牛新网了解,该模型已全量上线,支持通过自然语言指令进行交互,无需复杂的参数调整。开发者与创作者可通过以下渠道接入:
- 在线体验:访问官方体验中心 (
stepfun.com/studio/audio) 或 Demo 页面,直接测试语境控制效果。 - 开发集成:通过阶跃星辰开放平台获取 API 接口,集成至有声书、虚拟人、智能助手等产品中。
- Step Plan:已加入阶跃的 Step Plan 套餐,可直接调用。
这一升级标志着 TTS 技术从“读字”向“懂场景”的跨越,对于有声内容创作、游戏配音及智能座舱语音交互的拟人化体验具有显著提升。