ITCOW牛新网 6月30日消息,美团今日发布新一代万亿参数大模型——LongCat-2.0,并宣布将向全球开发者开源。该模型总参数量达1.6T,平均激活约48B(动态范围33B~56B),原生支持1M超长上下文窗口,是业界首个在五万卡国产算力集群上完成全流程预训练与推理的万亿参数MoE模型,标志着国产大模型在自主算力底座与超大规模训练工程上取得关键突破。
据ITCOW牛新网了解,LongCat-2.0预训练数据规模超30T Tokens,覆盖中、英、多语言及代码数据。面对万卡级国产集群训练中常见的硬件故障、通信异常与显存压力,美团团队从三方面攻克难题:稳定性上通过HCCL异常处理、弹性扩缩卡和自动故障恢复将月均日故障率降低70%以上;正确性上自研确定性算子并做Bitwise一致性验证,保障训练结果可靠;效率上通过流水线调度与显存优化使训练MFU提升1.5倍,最终实现稳态日吞吐超1T Tokens/天。
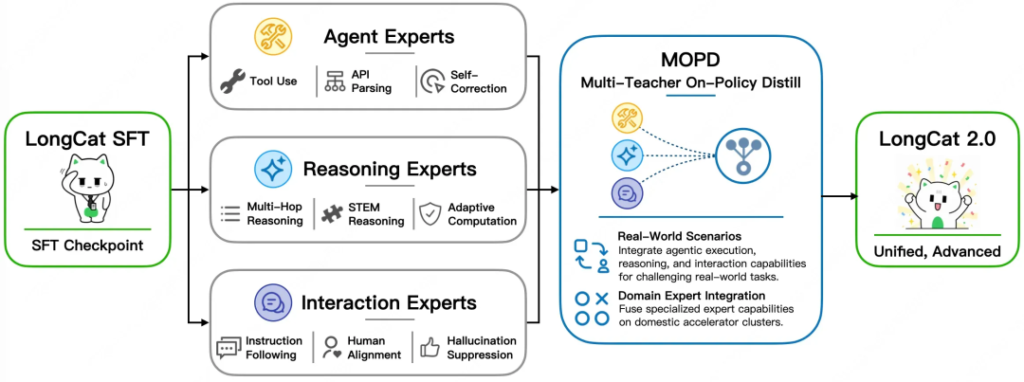
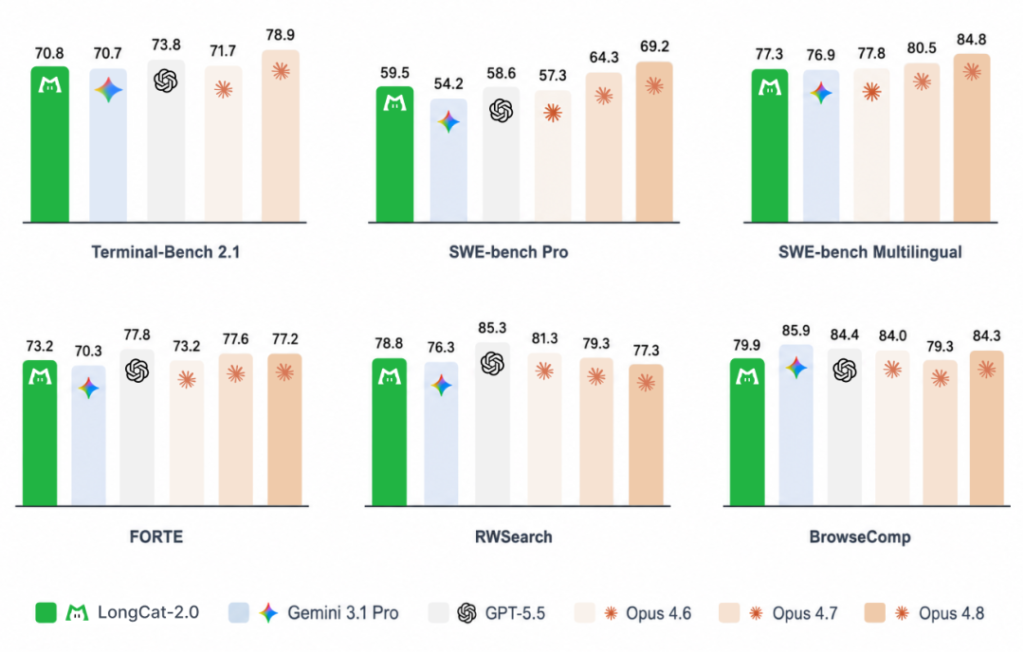
推理阶段,LongCat-2.0采用LongCat Sparse Attention(LSA)稀疏注意力机制将长文本计算量从平方级降至线性级,并通过零计算专家实现Token级动态激活——简单Token不消耗额外算力,复杂Token自动分配更多计算资源。模型采用MOPD架构融合Agent、Reasoning、Interaction三组专家能力,由门控网络按任务类型动态调度最擅长专家,而非简单参数合并。在编程能力评测SWE-bench Pro中取得59.5分,领先Gemini 3.1 Pro(54.2)、GPT-5.5(58.6)及Claude Opus 4.6(57.3);SWE-bench Multilingual得分77.3,与Claude Opus 4.6(77.8)基本持平;Terminal-Bench 2.1获70.8。搜索智能体评测RWSearch 78.8分、生产力场景FORTE 73.2分、BrowseComp 79.9分,均达或接近前沿闭源模型水平。
LongCat-2.0预览版已通过OpenRouter平台及官网longcat.ai向全球开发者开放调用,截至目前跻身OpenRouter全球大模型调用量前三;正式版开源权重行将放出。美团表示,希望通过在国产算力上验证万亿参数模型的完整训练—推理链路,为行业提供可复现的工程范本,也推动AI Agent在企业级场景中的务实落地。
API开放平台地址:https://longcat.chat/platform/product
